Analyse des sentiments dans Tableau avec Snowflake

Dans notre dernier article de blog - « Exécuter Python dans Tableau avec Snowflake » - nous avons fourni un exemple simple de la manière dont il est possible de tirer parti de la polyvalence du langage de programmation Python dans l'environnement familier de visualisation des données de Tableau, grâce à l'utilisation des fonctions définies par l'utilisateur (UDF) Python disponibles sur la plateforme Snowflake.
Dans cet article de blog, nous allons fournir un autre exemple de cette application, en analysant les tweets capturés lors de la finale de l'UEFA Champions League 2018. En particulier, nous montrerons comment utiliser VADER (Valence Aware Dictionary and Sentiment Reasoner), un modèle d'analyse des sentiments open source du nltk package (Natural Language Tool Kit), pour effectuer une analyse des sentiments de ces tweets.
Comme dans notre dernier article de blog, si vous souhaitez vivre une expérience plus pratique et avoir la possibilité d'utiliser Tableau, vous pouvez configurer un Compte d'essai Snowflake et suivez notre exemple.
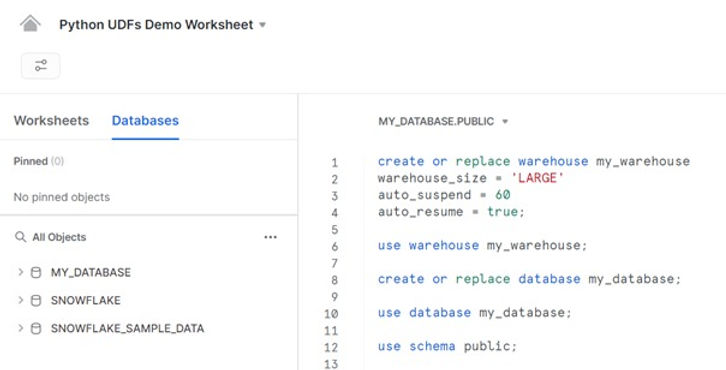
Nous allons commencer par configurer l'environnement de notre compte d'essai Snowflake, avec la création d'un entrepôt et d'une base de données :
oko
Les tweets que nous allons analyser se trouvent dans un fichier JSON, TweetsChampions.json, que vous pouvez télécharger depuis kaggle directement sur votre ordinateur (nous avons placé le fichier dans C:\temp \). Nous avons déjà utilisé ces données dans l'un de nos articles de blog précédents, nous vous encourageons donc à consulter ce site pour plus de détails sur la facilité avec laquelle il est possible d'analyser des données semi-structurées dans Snowflake. Pour l'instant, nous allons créer un format de fichier et un stage pour ce fichier :
create or replace file format tweets_file_format
type = json;
create or replace stage tweets_stage
file_format = tweets_file_format;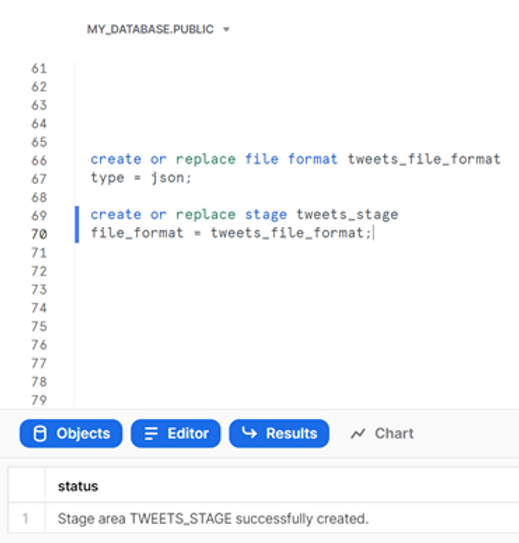
Ensuite, utilisez SnowSQL pour placer le fichier json dans le stage nouvellement créé :
utiliser la base de données MY_DATABASE ;
mettez le fichier ://C:\temp\TweetsChampions.json @tweets_stage ;

Nous allons ensuite exécuter une séquence de commandes SQL pour créer une table contenant les données JSON brutes, copier les données brutes du fichier JSON dans cette table, puis créer une autre table contenant les données des tweets sous forme de tableau, et enfin inspecter quelques entrées de cette table :
create or replace table raw_tweets (tweet variant);
copy into raw_tweets from @tweets_stage;
create or replace table summary_tweets as
select tweet:user:id::number as user_id,
tweet:user:followers_count::integer as user_followers_count,
tweet:id::number as tweet_id,
tweet:created_at::timestamp as tweet_date,
tweet:lang::string as tweet_language,
tweet:text::string as tweet_text
--,value:text::string as tweet_hashtag_text
from raw_tweets
--, lateral flatten(tweet:entities:hashtags)
where tweet_id is not null and tweet:possibly_sensitive=false
and hour(tweet_date)>17;
select * from summary_tweets where tweet_language = 'en' limit 10;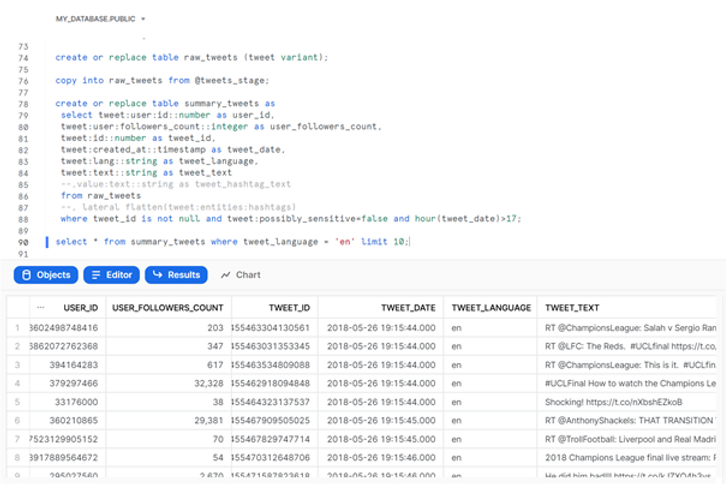
Maintenant que les tweets sont dans Snowflake, nous allons configurer notre analyse des sentiments. Le package nltk est disponible pour nous directement dans Snowflake, grâce au partenariat avec Anaconda, afin que nous puissions l'utiliser de la même manière que le forfait vacances de notre dernier billet de blog. En dehors de Snowflake, nous utiliserions directement la bibliothèque nltk pour télécharger le modèle d'analyse VADER. Cependant, en raison de Contraintes de sécurité liées à Snowflake, le téléchargement à la demande ne fonctionne pas avec les UDF Python. Pour contourner ce problème, nous devrons téléchargez le lexique VADER localement et fournissez-le à l'UDF via une scène Snowflake. Nous utiliserons à nouveau SnowSQL et placerons le fichier dans la phase utilisateur (pas besoin de créer une étape dédiée), en veillant à ce qu'il ne soit pas compressé :
put file://C:\temp\vader_lexicon.txt @~ auto_compress = false overwrite = true;

Nous pouvons maintenant créer notre UDF Python :
create or replace function getSentiment(mySentence string)
returns float
language pythonr
untime_version = 3.8
packages = ('nltk')
imports=('@~/vader_lexicon.txt')
handler = 'getScore'
as $$
import nltk
import sys
IMPORT_DIRECTORY_NAME = "snowflake_import_directory"
import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME]
def getScore(mySentence):
from nltk.sentiment.vader
import SentimentIntensityAnalyzer
lexicon_file = import_dir+'vader_lexicon.txt'
sentiment_analyzer = SentimentIntensityAnalyzer(lexicon_file)
sentiment_score = sentiment_analyzer.polarity_scores(mySentence)
['compound']
return sentiment_score
$$;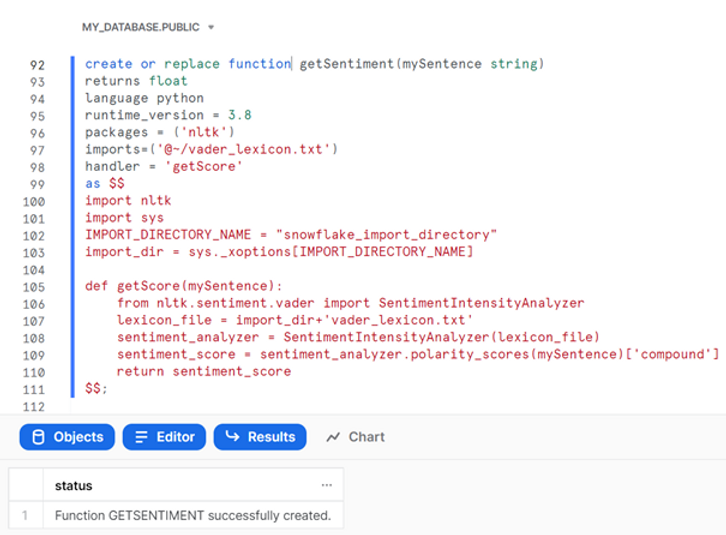
Cette fonction saisira une chaîne (qui sera finalement les tweets que nous voulons analyser) et renverra un flottant, correspondant au score de polarité composé VADER. Comme vous pouvez le constater, nous utilisons le package nltk et importons le fichier lexique VADER depuis notre espace utilisateur. Lorsque nous spécifiez le fichier d'importation, Snowflake copie le fichier généré dans le répertoire d'importation UDF en arrière-plan. Nous devons ensuite récupérer l'emplacement de ce répertoire d'importation à l'aide du système. méthode _xoptions dans notre code Python (encadrée par des symboles dollars). Enfin, nous pouvons définir notre fonction et demander à nltk d'utiliser le lexique VADER et de renvoyer un score d'analyse des sentiments.
Nous pouvons exécuter notre fonction sur un exemple simple :
select getSentiment('I love Argusa!'), getSentiment('I hate the rain');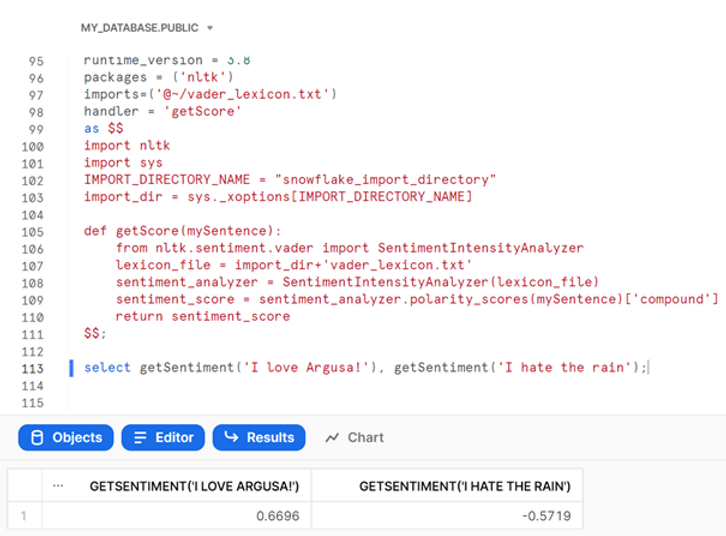
Le score de sentiment composé de VADER est compris entre -1 (le plus négatif) et 1 (le plus positif). Notre fonction semble donc fonctionner !
Passons maintenant à Tableau Desktop et poursuivons notre analyse. Nous allons faire glisser le tableau récapitulatif des tweets à des fins d'analyse et appliquer un filtre de source de données pour nous concentrer sur les tweets en anglais :
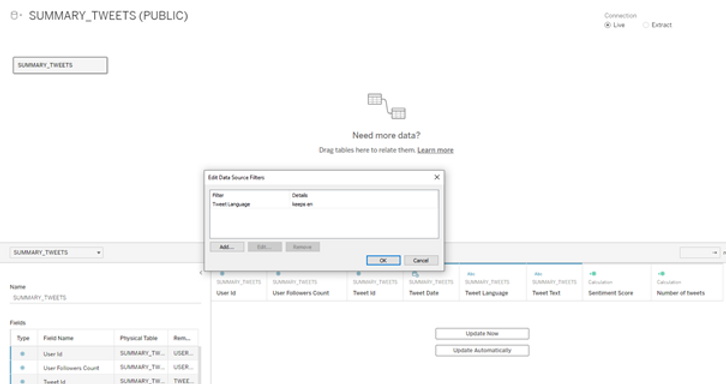
Nous pouvons ensuite produire une visualisation simple du nombre de tweets (nombre distinct de l'identifiant du Tweet) au fil du temps (date exacte du Tweet) :
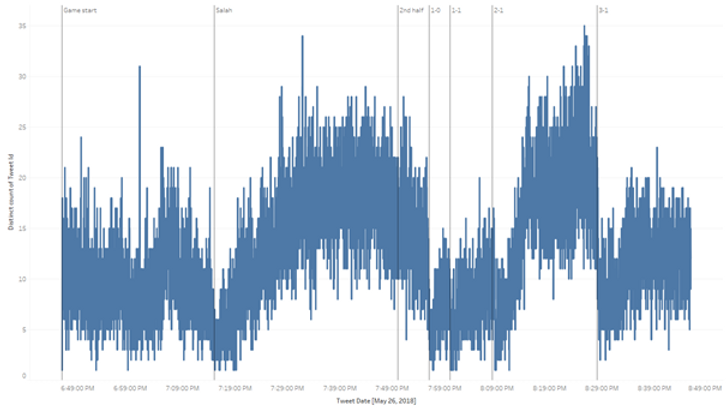
Dans cet exemple, nous avons ajouté quelques lignes de référence indiquant les événements importants survenus tout au long du match, afin de faciliter notre analyse. Il est intéressant de constater, par exemple, que le nombre de tweets diminue de manière significative immédiatement après le but marqué.
Nous allons maintenant utiliser Les fonctions intermédiaires de Tableau pour exécuter notre UDF Snowflake « GetSentiment » :
RAWSQL_REAL(
"select public.getSentiment(%1)", [Tweet Text]
)
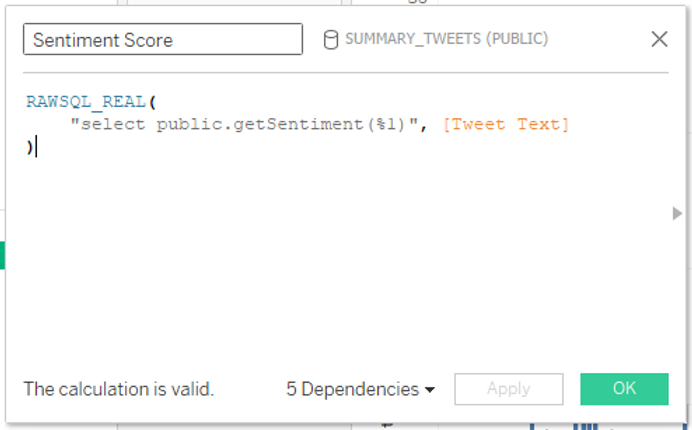
Nous devrions remplacer l'agrégation par défaut de notre score de sentiment par une moyenne, car cela n'a aucun sens de faire la somme par défaut pour cette mesure. Nous pouvons ensuite modifier légèrement notre visualisation en faisant glisser le calcul du score de sentiment vers la marque de couleur et en remplaçant le champ Date du tweet par Minute des données du Tweet, au lieu de la date exacte :
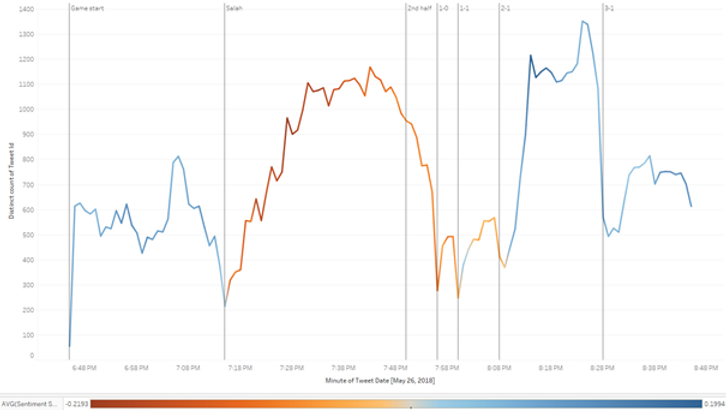
Avec cette nouvelle visualisation, nous pouvons voir un nombre stable de tweets publiés avec, en moyenne, des sentiments positifs au cours des 30 premières minutes de jeu.
Vers 19 h 15 (deuxième ligne de référence), le joueur de Liverpool Salah a été remplacé en raison d'une blessure subie alors qu'il affrontait le joueur du Real Madrid Ramos pour le ballon. Cet événement a suscité des réactions de colère de la part des fans de Salah, dont les insultes ont fait la une des journaux sur Twitter. Cela se voit bien dans notre visualisation, car le nombre de tweets publiés augmente régulièrement après la blessure de Salah, et le sentiment moyen des tweets devient négatif.
Le nombre de tweets a diminué en seconde période, mais le sentiment moyen des tweets est resté négatif, au moins jusqu'à environ 20 h 10, date à laquelle le Real Madrid a assuré la victoire en marquant le deuxième but. À ce stade, nous observons une nouvelle augmentation du nombre de tweets et une évolution positive du sentiment moyen.
Voici une autre visualisation qui montre le score de sentiment moyen des tweets (hors retweets) mentionnant 5 personnes différentes impliquées dans la finale de la Ligue des Champions :
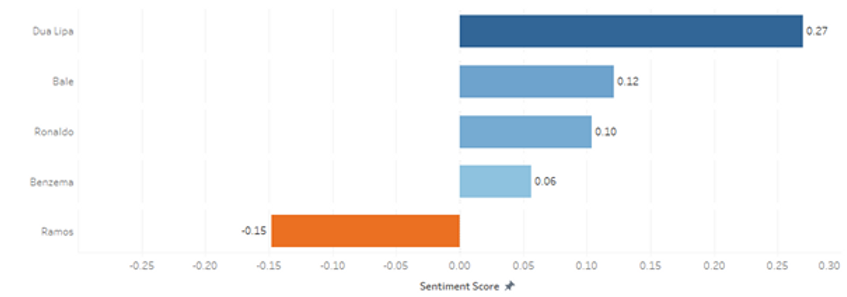
Nous pouvons constater que, sur les 5 personnes analysées, seul Ramos a des scores négatifs moyens, en raison de l'incident avec Salah mentionné précédemment.
Mais tout n'est pas négatif. Les tweets mentionnant Dua Lipa, la chanteuse qui s'est produite lors de la cérémonie d'ouverture, sont, en moyenne, les plus positifs des 5 personnes analysées. En fait, les deux tweets ayant obtenu le score de sentiment le plus élevé (0,968 et 0,962) de notre ensemble de données concernent la performance du chanteur :

Nous attirons votre attention sur le fait que ces scores de sentiment sont calculés à l'aide de modèles d'analyse Python complexes. Mais grâce à Snowflake et Tableau, il est facile d'accéder à ces modèles dans des environnements familiers, et de produire et d'analyser des résultats sans pratiquement aucun codage !
Dans notre dernier article de blog - « Exécuter Python dans Tableau avec Snowflake » - nous avons fourni un exemple simple de la manière dont il est possible de tirer parti de la polyvalence du langage de programmation Python dans l'environnement familier de visualisation des données de Tableau, grâce à l'utilisation des fonctions définies par l'utilisateur (UDF) Python disponibles sur la plateforme Snowflake.
Dans cet article de blog, nous allons fournir un autre exemple de cette application, en analysant les tweets capturés lors de la finale de l'UEFA Champions League 2018. En particulier, nous montrerons comment utiliser VADER (Valence Aware Dictionary and Sentiment Reasoner), un modèle d'analyse des sentiments open source du nltk package (Natural Language Tool Kit), pour effectuer une analyse des sentiments de ces tweets.
Comme dans notre dernier article de blog, si vous souhaitez vivre une expérience plus pratique et avoir la possibilité d'utiliser Tableau, vous pouvez configurer un Compte d'essai Snowflake et suivez notre exemple.
Nous allons commencer par configurer l'environnement de notre compte d'essai Snowflake, avec la création d'un entrepôt et d'une base de données :
oko
Les tweets que nous allons analyser se trouvent dans un fichier JSON, TweetsChampions.json, que vous pouvez télécharger depuis kaggle directement sur votre ordinateur (nous avons placé le fichier dans C:\temp \). Nous avons déjà utilisé ces données dans l'un de nos articles de blog précédents, nous vous encourageons donc à consulter ce site pour plus de détails sur la facilité avec laquelle il est possible d'analyser des données semi-structurées dans Snowflake. Pour l'instant, nous allons créer un format de fichier et un stage pour ce fichier :
create or replace file format tweets_file_format
type = json;
create or replace stage tweets_stage
file_format = tweets_file_format;Ensuite, utilisez SnowSQL pour placer le fichier json dans le stage nouvellement créé :
utiliser la base de données MY_DATABASE ;
mettez le fichier ://C:\temp\TweetsChampions.json @tweets_stage ;
Nous allons ensuite exécuter une séquence de commandes SQL pour créer une table contenant les données JSON brutes, copier les données brutes du fichier JSON dans cette table, puis créer une autre table contenant les données des tweets sous forme de tableau, et enfin inspecter quelques entrées de cette table :
create or replace table raw_tweets (tweet variant);
copy into raw_tweets from @tweets_stage;
create or replace table summary_tweets as
select tweet:user:id::number as user_id,
tweet:user:followers_count::integer as user_followers_count,
tweet:id::number as tweet_id,
tweet:created_at::timestamp as tweet_date,
tweet:lang::string as tweet_language,
tweet:text::string as tweet_text
--,value:text::string as tweet_hashtag_text
from raw_tweets
--, lateral flatten(tweet:entities:hashtags)
where tweet_id is not null and tweet:possibly_sensitive=false
and hour(tweet_date)>17;
select * from summary_tweets where tweet_language = 'en' limit 10;Maintenant que les tweets sont dans Snowflake, nous allons configurer notre analyse des sentiments. Le package nltk est disponible pour nous directement dans Snowflake, grâce au partenariat avec Anaconda, afin que nous puissions l'utiliser de la même manière que le forfait vacances de notre dernier billet de blog. En dehors de Snowflake, nous utiliserions directement la bibliothèque nltk pour télécharger le modèle d'analyse VADER. Cependant, en raison de Contraintes de sécurité liées à Snowflake, le téléchargement à la demande ne fonctionne pas avec les UDF Python. Pour contourner ce problème, nous devrons téléchargez le lexique VADER localement et fournissez-le à l'UDF via une scène Snowflake. Nous utiliserons à nouveau SnowSQL et placerons le fichier dans la phase utilisateur (pas besoin de créer une étape dédiée), en veillant à ce qu'il ne soit pas compressé :
put file://C:\temp\vader_lexicon.txt @~ auto_compress = false overwrite = true;
Nous pouvons maintenant créer notre UDF Python :
create or replace function getSentiment(mySentence string)
returns float
language pythonr
untime_version = 3.8
packages = ('nltk')
imports=('@~/vader_lexicon.txt')
handler = 'getScore'
as $$
import nltk
import sys
IMPORT_DIRECTORY_NAME = "snowflake_import_directory"
import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME]
def getScore(mySentence):
from nltk.sentiment.vader
import SentimentIntensityAnalyzer
lexicon_file = import_dir+'vader_lexicon.txt'
sentiment_analyzer = SentimentIntensityAnalyzer(lexicon_file)
sentiment_score = sentiment_analyzer.polarity_scores(mySentence)
['compound']
return sentiment_score
$$;
Cette fonction saisira une chaîne (qui sera finalement les tweets que nous voulons analyser) et renverra un flottant, correspondant au score de polarité composé VADER. Comme vous pouvez le constater, nous utilisons le package nltk et importons le fichier lexique VADER depuis notre espace utilisateur. Lorsque nous spécifiez le fichier d'importation, Snowflake copie le fichier généré dans le répertoire d'importation UDF en arrière-plan. Nous devons ensuite récupérer l'emplacement de ce répertoire d'importation à l'aide du système. méthode _xoptions dans notre code Python (encadrée par des symboles dollars). Enfin, nous pouvons définir notre fonction et demander à nltk d'utiliser le lexique VADER et de renvoyer un score d'analyse des sentiments.
Nous pouvons exécuter notre fonction sur un exemple simple :
select getSentiment('I love Argusa!'), getSentiment('I hate the rain');Le score de sentiment composé de VADER est compris entre -1 (le plus négatif) et 1 (le plus positif). Notre fonction semble donc fonctionner !
Passons maintenant à Tableau Desktop et poursuivons notre analyse. Nous allons faire glisser le tableau récapitulatif des tweets à des fins d'analyse et appliquer un filtre de source de données pour nous concentrer sur les tweets en anglais :
Nous pouvons ensuite produire une visualisation simple du nombre de tweets (nombre distinct de l'identifiant du Tweet) au fil du temps (date exacte du Tweet) :
Dans cet exemple, nous avons ajouté quelques lignes de référence indiquant les événements importants survenus tout au long du match, afin de faciliter notre analyse. Il est intéressant de constater, par exemple, que le nombre de tweets diminue de manière significative immédiatement après le but marqué.
Nous allons maintenant utiliser Les fonctions intermédiaires de Tableau pour exécuter notre UDF Snowflake « GetSentiment » :
RAWSQL_REAL(
"select public.getSentiment(%1)", [Tweet Text]
)
Nous devrions remplacer l'agrégation par défaut de notre score de sentiment par une moyenne, car cela n'a aucun sens de faire la somme par défaut pour cette mesure. Nous pouvons ensuite modifier légèrement notre visualisation en faisant glisser le calcul du score de sentiment vers la marque de couleur et en remplaçant le champ Date du tweet par Minute des données du Tweet, au lieu de la date exacte :
Avec cette nouvelle visualisation, nous pouvons voir un nombre stable de tweets publiés avec, en moyenne, des sentiments positifs au cours des 30 premières minutes de jeu.
Vers 19 h 15 (deuxième ligne de référence), le joueur de Liverpool Salah a été remplacé en raison d'une blessure subie alors qu'il affrontait le joueur du Real Madrid Ramos pour le ballon. Cet événement a suscité des réactions de colère de la part des fans de Salah, dont les insultes ont fait la une des journaux sur Twitter. Cela se voit bien dans notre visualisation, car le nombre de tweets publiés augmente régulièrement après la blessure de Salah, et le sentiment moyen des tweets devient négatif.
Le nombre de tweets a diminué en seconde période, mais le sentiment moyen des tweets est resté négatif, au moins jusqu'à environ 20 h 10, date à laquelle le Real Madrid a assuré la victoire en marquant le deuxième but. À ce stade, nous observons une nouvelle augmentation du nombre de tweets et une évolution positive du sentiment moyen.
Voici une autre visualisation qui montre le score de sentiment moyen des tweets (hors retweets) mentionnant 5 personnes différentes impliquées dans la finale de la Ligue des Champions :
Nous pouvons constater que, sur les 5 personnes analysées, seul Ramos a des scores négatifs moyens, en raison de l'incident avec Salah mentionné précédemment.
Mais tout n'est pas négatif. Les tweets mentionnant Dua Lipa, la chanteuse qui s'est produite lors de la cérémonie d'ouverture, sont, en moyenne, les plus positifs des 5 personnes analysées. En fait, les deux tweets ayant obtenu le score de sentiment le plus élevé (0,968 et 0,962) de notre ensemble de données concernent la performance du chanteur :
Nous attirons votre attention sur le fait que ces scores de sentiment sont calculés à l'aide de modèles d'analyse Python complexes. Mais grâce à Snowflake et Tableau, il est facile d'accéder à ces modèles dans des environnements familiers, et de produire et d'analyser des résultats sans pratiquement aucun codage !