Suivi des changements temporels dans la modélisation dimensionnelle avec WhereScape

Dans le monde de l'entreposage de données, la modélisation dimensionnelle est l'un des moyens les plus simples et les plus directs de présenter des données aux utilisateurs. Ce type de modélisation divise les données en faits, principalement des données quantitatives qui représentent des mesures à des moments spécifiques, et des dimensions, des attributs qualitatifs qui décrivent le contexte dans lequel les mesures sont prises. Par exemple, dans le cas où « une voiture a été vendue en Allemagne pour 20 000 euros », « 20 000 euros » est un fait et « Allemagne » est un attribut (donc une dimension).
Cet article traite spécifiquement des différentes manières de traiter l'évolution des attributs au fil du temps. Cela peut inclure des produits qui changent de nom, des personnes qui changent d'adresse, etc.
Le livre « The data Warehouse Toolkit », de R. Kimball et M. Ross, décrit en détail huit méthodes permettant de suivre les changements temporels dans la modélisation dimensionnelle. Nous aborderons ici un sous-ensemble de ces méthodes, en utilisant la notation introduite par les auteurs dans le livre.
Type 0 : Conserver l'original
Cette méthode est la plus simple et convient au traitement de tout champ dont le nom est « original » (ou équivalent). Ces valeurs ne peuvent tout simplement pas être modifiées. Si une nouvelle valeur est trouvée, elle est supprimée et la valeur d'origine est conservée.
Type 1 : Remplacer
Cette méthode convient aux modifications liées à des erreurs ou au traitement de domaines pour lesquels l'entreprise n'est pas intéressée par le suivi des changements temporels. La méthode consiste à remplacer la valeur précédente. Les clients qui modifient leur date d'anniversaire en sont un exemple. La date de naissance d'une personne ne peut normalement pas changer. Nous pouvons donc supposer que, si elle change, c'est dû à une faute de frappe. Pour cette raison, nous allons supprimer la date d'anniversaire précédente et conserver toujours la dernière valeur. C'est le contraire de l'approche de type 0.
Type 2 : Ajouter une nouvelle ligne
Ici, nous commençons réellement à suivre les modifications. La méthode de type 2 ajoute une nouvelle ligne à la dimension. Les nouveaux faits seront liés à la nouvelle clé et les anciens resteront liés à l'ancienne clé. Un cas d'utilisation de cette approche serait de changer d'adresse. À des fins d'analyse, nous souhaiterions conserver les informations d'adresse à partir desquelles chaque vente a été effectuée. Dans le cas contraire, nous pourrions assister à des changements dans les mesures, par exemple les délais de livraison, qui ne seraient pas explicables si nous remplacions également l'adresse pour les anciennes ventes (qui serait de type 1).
Dans cette méthode, certains attributs doivent être ajoutés sur chaque ligne de la dimension. Les attributs 1 et 2 sont obligatoires et les autres sont facultatifs :
- Date de début : date à partir de laquelle l'enregistrement est valide
- Date de fin : date jusqu'à laquelle l'enregistrement est valide
- Drapeau actuel : Cela indique l'entrée actuellement active, pour faciliter le filtrage
- Date de modification : date à laquelle la modification a été enregistrée dans l'entrepôt de données, qui peut être différente de la date à laquelle le client a changé d'adresse
- Motif du changement : pour suivre quel attribut d'une dimension a provoqué la création d'une nouvelle ligne.
Type 3 : Ajouter une nouvelle colonne (ou une réalité alternative)
Cette méthode est utile lorsqu'un changement fondamental se produit dans la façon dont un attribut est défini et que l'entreprise souhaite suivre l'attribut dans son ancienne et sa nouvelle définition. Les modifications apportées à la catégorisation des produits à la suite d'une fusion avec une autre société en sont un exemple typique. Un téléviseur pouvait auparavant être classé dans la catégorie « électronique » et dans la catégorie « média » dans la nouvelle entreprise. Les analystes veulent être en mesure de choisir la catégorisation à prendre en compte. Dans ce cas, une nouvelle colonne est ajoutée aux dimensions en mappant l'ancienne valeur à la nouvelle valeur.
Type 4 : Ajouter une mini-dimension
Parfois, dans une dimension, certains attributs changent à des vitesses différentes. Par exemple, dans la dimension client, il peut y avoir l'adresse qui change normalement toutes les quelques années, et le mode de livraison préféré actuel, qui peut changer même tous les jours car il est souvent modifiable d'un simple clic sur un site Web. Le suivi de cet attribut à l'aide de l'approche de type 2 peut entraîner une augmentation rapide du nombre de lignes dans la dimension, ce qui rend les requêtes sur des paramètres à évolution lente moins performantes. La solution consiste à scinder la dimension client en deux, chacune ayant sa propre clé primaire dans la table des faits séparément. L'un suivra les attributs qui changent lentement et l'autre ceux qui changent rapidement.
Type 5 : Ajoutez une mini-dimension et un stabilisateur de type 1
Cette méthode est similaire au type 4, mais elle inclut en outre la clé primaire de la dimension à évolution rapide en tant que clé étrangère vers la table de dimensions « principale », c'est-à-dire la table contenant la dimension à évolution lente. Cela permet de relier directement les deux dimensions sans passer par un tableau de faits. D'autre part, la table de dimensions « principale » ne peut contenir que la version « actuelle » de l'attribut qui évolue rapidement.
Automatisez le tout à l'aide de WhereScape
Tout cela semble compliqué à implémenter en écrivant du SQL explicite ? Il existe une solution pour vous. Heureusement, ces méthodes sont basées sur des règles simples et se prêtent donc facilement à l'automatisation ! Où se trouve Scape est un leader avec 20 ans d'expérience dans l'automatisation des entrepôts de données. Lorsque vous utilisez WhereScape, vous choisissez le type de suivi des modifications que vous souhaitez, et un assistant vous aidera à configurer l'implémentation sans avoir à écrire une seule ligne de code. De plus, cette œuvre est facilement réutilisable pour plusieurs dimensions. Si vous souhaitez vous écarter des règles standard définies par Kimball, il est possible de modifier et de personnaliser le modèle qui génère le code, et d'automatiser ainsi la création de votre propre algorithme de suivi des modifications.
Voyons maintenant comment cela fonctionne. Dans l'exemple suivant, nous supposerons que les données sont déjà chargées dans la base de données cible dans une table par étapes contenant des informations sur les marchés, notamment leur localisation et leurs caractéristiques.
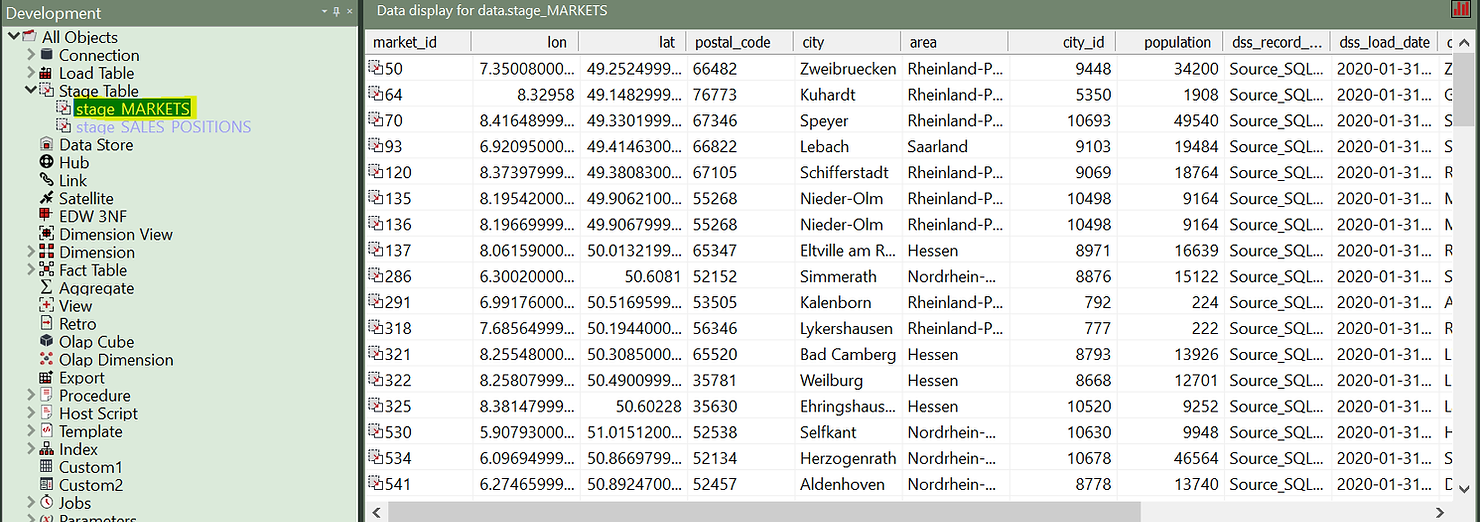
Les tables d'étape sont des tables de travail dans lesquelles des transformations sont effectuées sur les données avant de les charger dans les objets finaux (dimensions ou tables de faits). Les tables d'étapes sont généralement temporaires et tronquées à chaque cycle de charge. Cette table d'étape peut provenir de plusieurs tables sources et implémenter déjà une logique métier complexe. C'est un bon sujet pour un autre article. Pour l'instant, nous allons nous concentrer sur la manière de créer une dimension de type 2 à évolution lente à partir de ce tableau d'étapes.
Il suffit de cliquer sur le type d'élément « Dimension » dans le volet de gauche, puis de faire glisser et déposer le tableau des étapes dans la zone de travail.
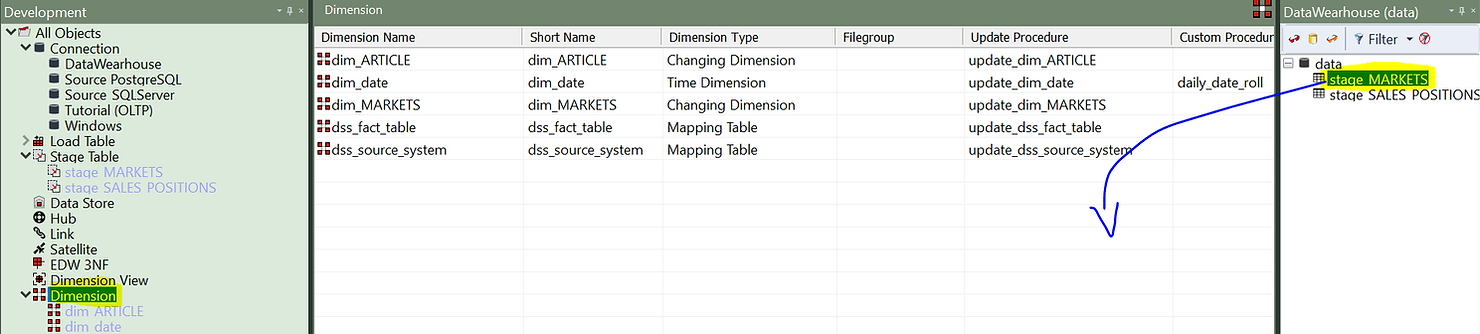
Un assistant s'affichera pour vous aider à configurer votre nouvelle dimension.
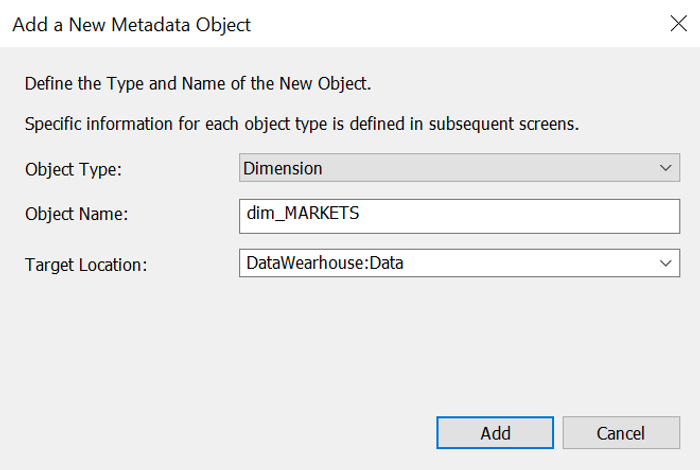
Tout d'abord, il faut lui donner un nom. Notez que l'assistant propose un nom pour cette table, conformément aux meilleures pratiques en matière d'entrepôt de données : il utilise le nom de la table de stage et remplace « stage » par « dim ». Vous pouvez bien entendu personnaliser la convention de dénomination ainsi que le nom d'une entité unique que vous ne souhaitez pas suivre. De plus, vous pouvez choisir l'endroit où vous souhaitez stocker votre dimension. Par exemple, les entités stockées de manière permanente (sous forme de dimensions) sont généralement stockées dans un emplacement doté de fonctionnalités de sauvegarde plus robustes.
La deuxième fenêtre vous demande quel type de dimensions vous souhaitez créer. Comme vous pouvez le constater, les types 1, 2 et 3 sont possibles. Vous pouvez également choisir d'utiliser des horodatages générés par le système ou des horodatages pilotés par les données. Pour cet exemple, nous allons choisir « Slowly Changing » (Type 2).

La fenêtre suivante vous permettra de documenter entièrement votre dimension, y compris son grain, sa destination et son utilisation. Toutes ces informations apparaîtront dans la documentation produite automatiquement.
Plus important encore, l'assistant créera le code qui gérera les insertions et les mises à jour. La modification du DDL (langage de définition des données) est également possible si nécessaire. Pour personnaliser la procédure de mise à jour, cliquez sur « Reconstruire ».
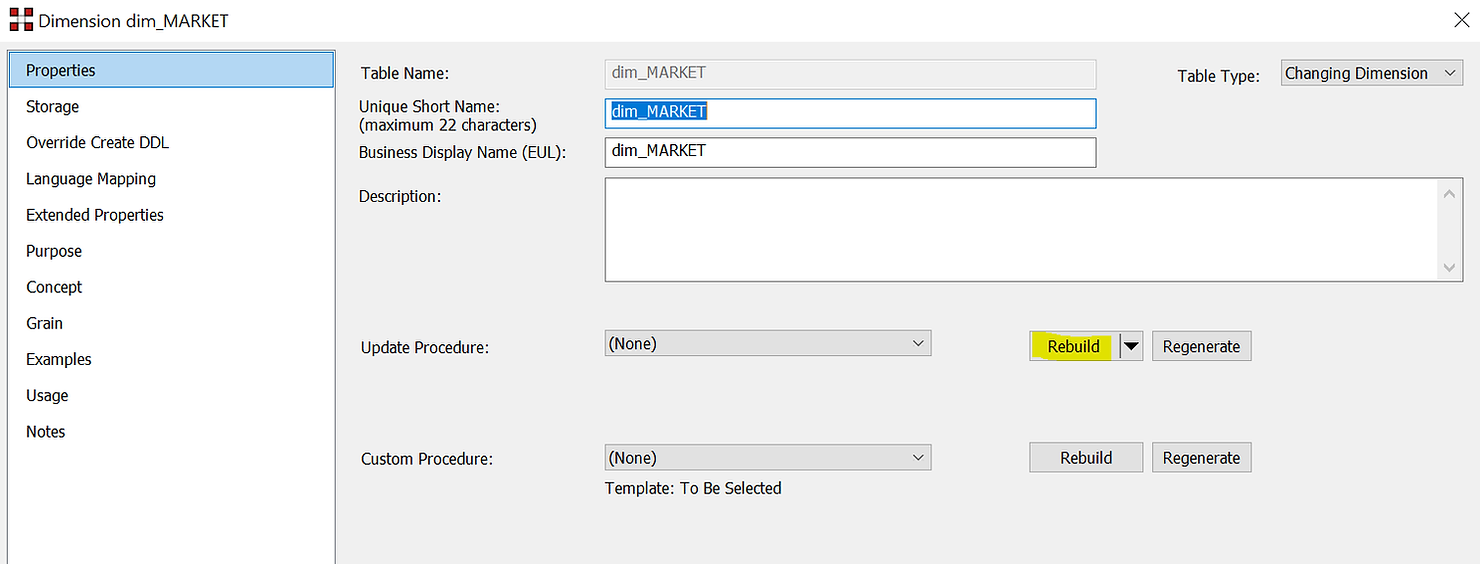
Dans la fenêtre suivante, vous pouvez choisir « Créer » ou « Créer et charger ». La raison en est qu'il peut s'agir d'une grande table et que le chargement peut prendre beaucoup de temps. Vous pouvez donc facilement décider de ne pas charger les dimensions immédiatement après leur création, mais plus tard, en arrière-plan, via un planificateur.
Dans la fenêtre suivante, il vous est demandé de configurer la clé métier, c'est-à-dire le champ qui identifie un élément métier. Il peut s'agir d'un client, d'un produit ou, dans ce cas, d'un marché. Nous choisirons « market_id ». Au bas de cette fenêtre, vous trouverez une description utile de l'élément que vous êtes en train de modifier.
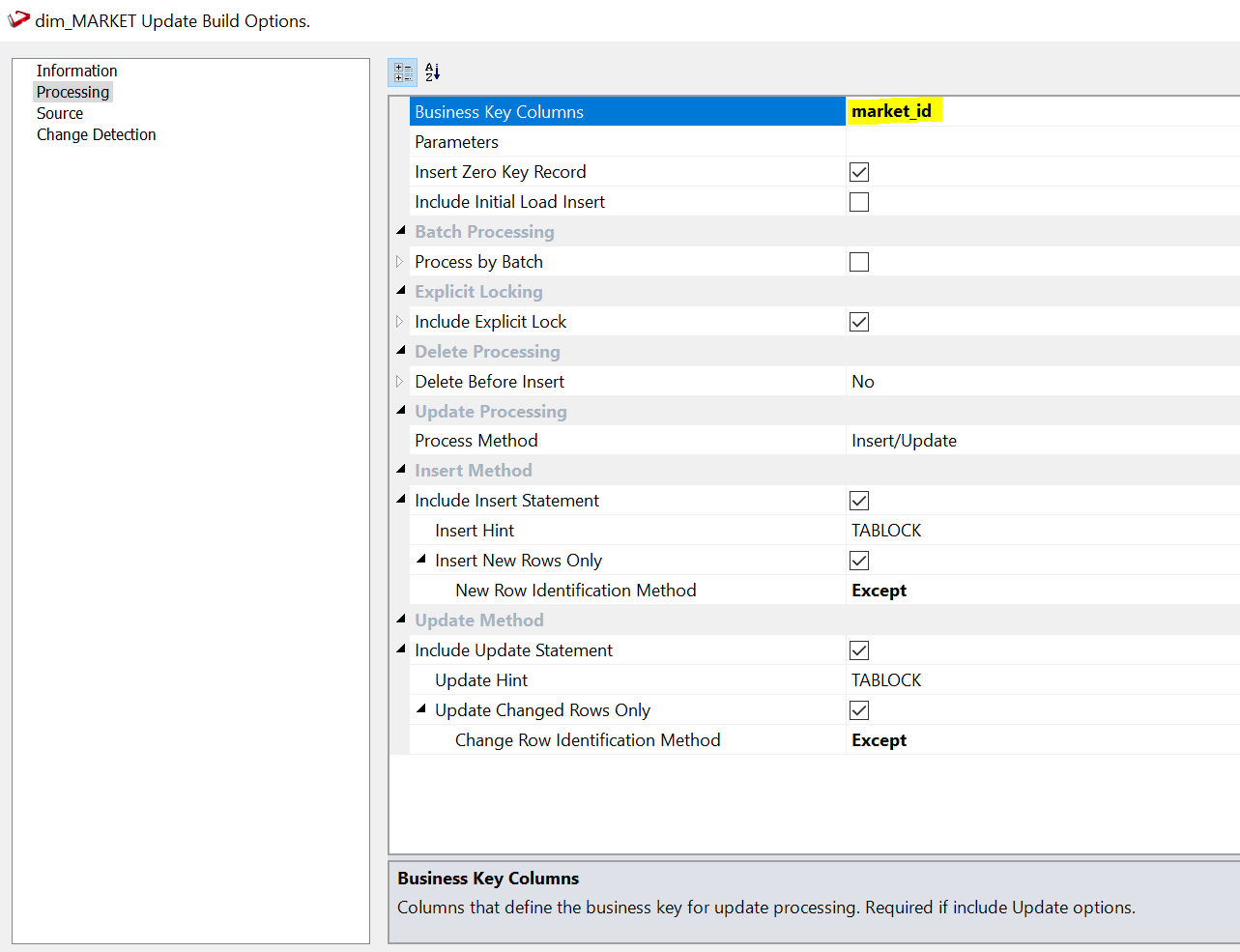
Nous avons la possibilité de configurer toutes sortes d'options, mais les valeurs par défaut fonctionnent bien dans la plupart des cas d'utilisation. La dernière étape consiste à décider des attributs dont nous voulons suivre les modifications. Vous pouvez le faire dans la section « Détection des modifications ».
Le choix vous appartient à vous et à vos représentants commerciaux. Pour cet exemple, nous allons choisir la population et la zone. Un marché représente un lieu spécifique, de sorte que sa longitude et sa latitude ne changent pas aussi bien que le nom de la ville dans laquelle il se trouve. S'ils changent, cela est probablement dû à une erreur. Nous ne voulons donc pas suivre ce changement dans le temps. D'autre part, la population et la superficie sont mesurées chaque année et, dans les zones en développement rapide, elles peuvent changer rapidement. Et il peut être intéressant de suivre le contexte dans lequel se situaient les anciennes ventes. Nous allons donc suivre l'évolution de ces deux attributs.
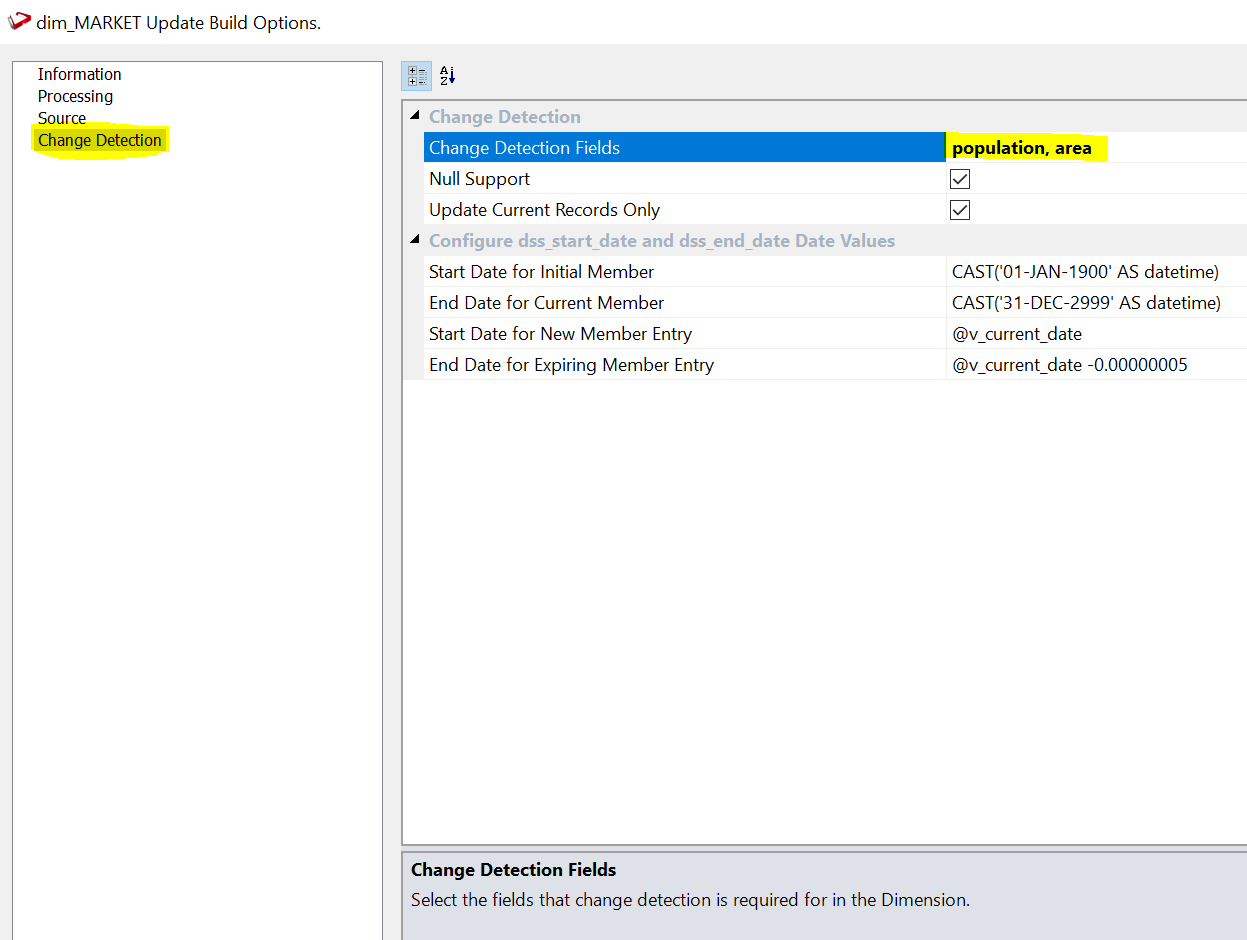
Maintenant, nous cliquons sur « OK » et notre dimension est prête.
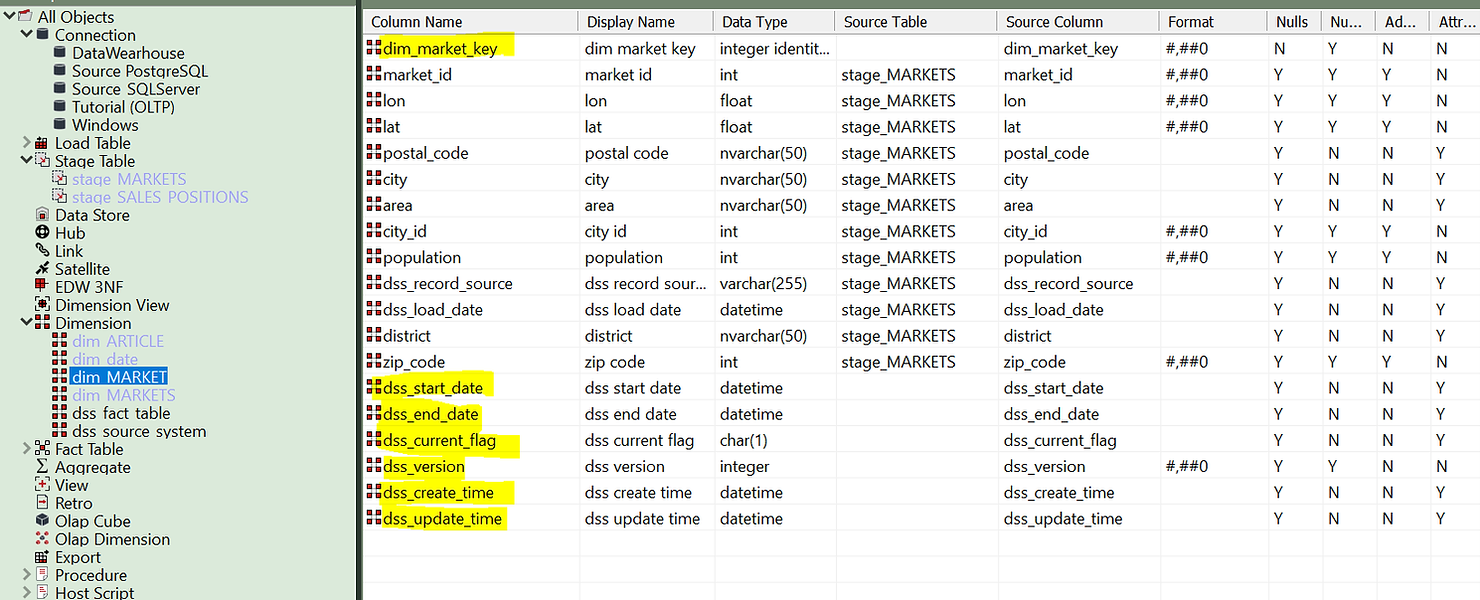
Notez que quelques champs ont été automatiquement créés. Il s'agit notamment de la clé de substitution numérique à utiliser comme clé étrangère dans la table de faits et de tous les attributs de modification : dates de début et de fin de validité, indicateur actuel, version, heure de première création et heures de dernière mise à jour. Au fur et à mesure de l'évolution de l'entrepôt de données, ces champs se géreront d'eux-mêmes grâce à la procédure de mise à jour prédéfinie que vous avez configurée à l'aide de l'assistant.
Dans la rubrique « Procédures », nous sommes en mesure d'inspecter le code généré et de le modifier si nécessaire. Sous « Modèles », il est également possible de modifier le modèle qui génère le code, de manière à ce que toutes les dimensions futures soient créées avec nos personnalisations.
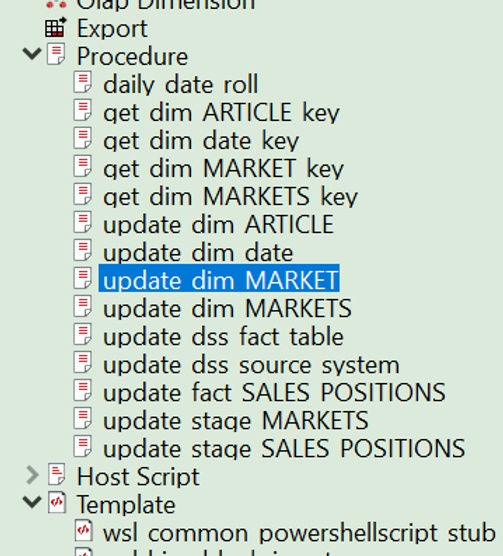
Les modèles WhereScape sont complets et gèrent non seulement la gestion des entités, mais également la journalisation des événements et des erreurs afin de garder facilement le contrôle de votre entrepôt de données. Soyez assuré que WhereScape offre toujours la possibilité de configurer des modèles manuellement pour couvrir des cas d'utilisation exceptionnels.
Pour terminer cet exemple, nous pouvons cliquer sur la dimension et voir son schéma :
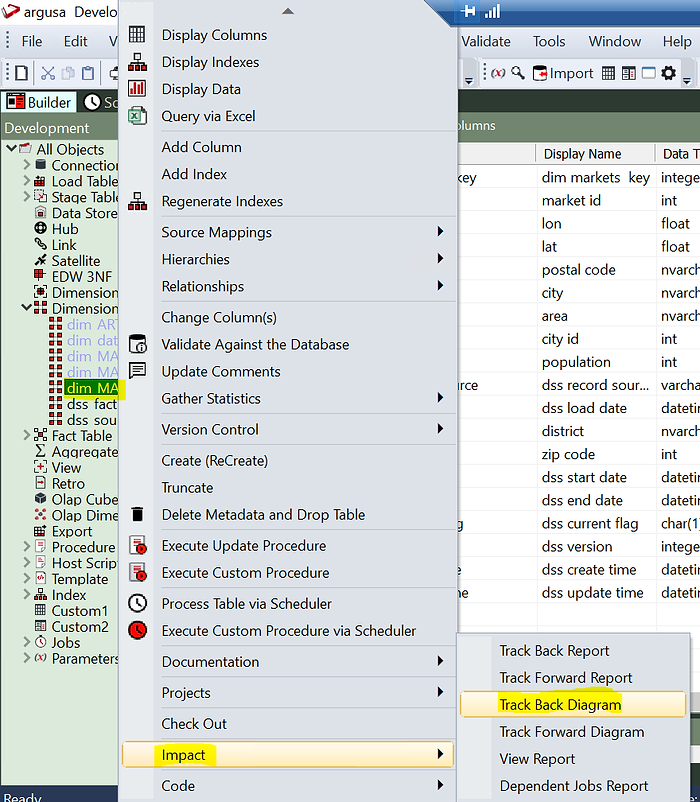
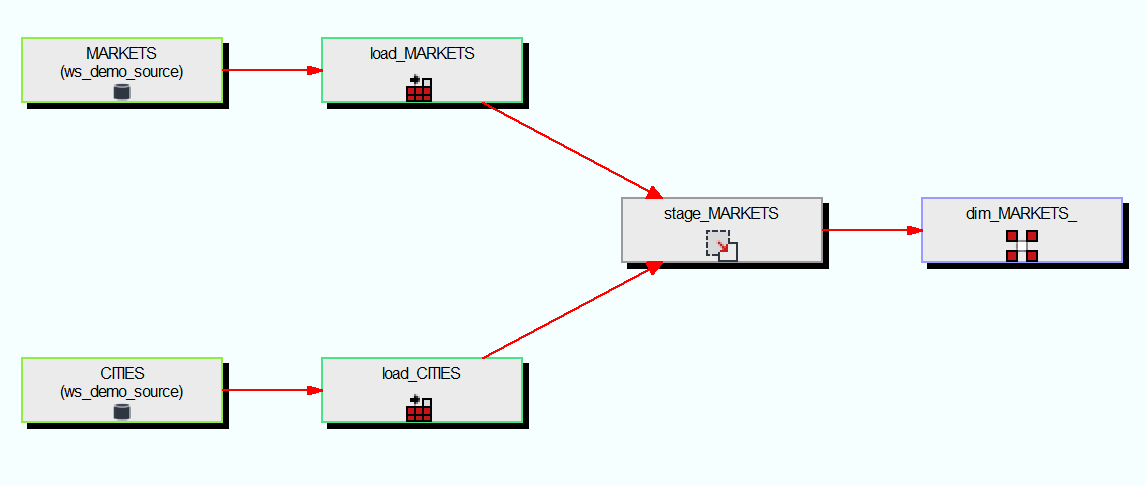
(Comme vous pouvez le voir sur le schéma, la table de stage ne provenait pas directement d'une table source mais il s'agit d'une jointure entre deux tables sources).
Enfin, il est temps de charger les données. Nous pouvons le faire très simplement en créant une tâche à partir du diagramme de flux et en l'exécutant dans le planificateur.
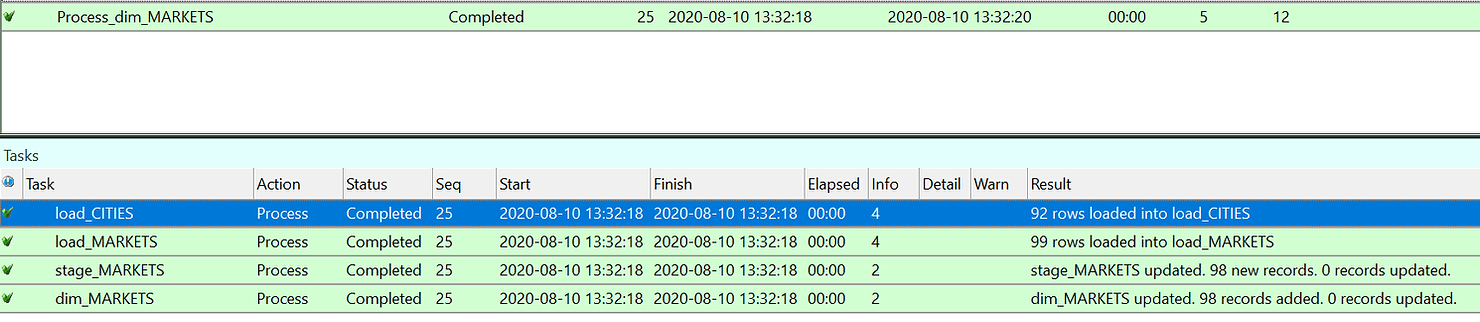
Comme vous pouvez le voir dans le journal des tâches, les tables VILLES et MARCHÉS ont d'abord été chargées à partir de la source, puis la table par étapes a été créée et enfin les dimensions remplies.
Juste à titre de test, essayons à nouveau d'exécuter le même travail.
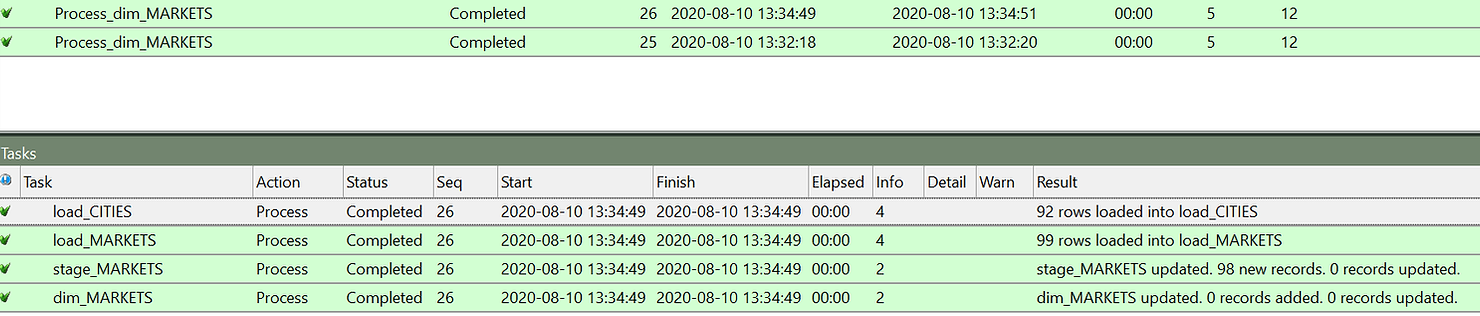
Comme vous pouvez le constater, cette fois, les 3 premières étapes ont été exécutées de la même manière et le tableau des étapes était rempli. Mais les données étant les mêmes, aucune modification n'a été détectée et aucune mise à jour n'a donc été effectuée sur la table des dimensions.
Pour terminer, essayons de modifier une entrée pour vérifier si nos dimensions fonctionnent. Je vais notamment modifier la population d'une zone de marché. Pour recharger les données, il suffit de cliquer sur « Démarrer la tâche » sur la même tâche que nous venons de lancer pour effectuer une deuxième exécution.

Cette fois, il met à jour une ligne dans dim_markets. Et nous pouvons également vérifier quel est le résultat sur le tableau.

Il existe désormais deux lignes pour Kuhardt avec le même market_id, la clé métier, mais deux dim_markets_key différentes, qui est la clé de substitution créée automatiquement par WhereScape qui sera utilisée pour rejoindre la table de faits. Enfin, ces données incluent également les dates de début et de fin gérées automatiquement et le drapeau actuel pour chaque enregistrement.
Dans le monde de l'entreposage de données, la modélisation dimensionnelle est l'un des moyens les plus simples et les plus directs de présenter des données aux utilisateurs. Ce type de modélisation divise les données en faits, principalement des données quantitatives qui représentent des mesures à des moments spécifiques, et des dimensions, des attributs qualitatifs qui décrivent le contexte dans lequel les mesures sont prises. Par exemple, dans le cas où « une voiture a été vendue en Allemagne pour 20 000 euros », « 20 000 euros » est un fait et « Allemagne » est un attribut (donc une dimension).
Cet article traite spécifiquement des différentes manières de traiter l'évolution des attributs au fil du temps. Cela peut inclure des produits qui changent de nom, des personnes qui changent d'adresse, etc.
Le livre « The data Warehouse Toolkit », de R. Kimball et M. Ross, décrit en détail huit méthodes permettant de suivre les changements temporels dans la modélisation dimensionnelle. Nous aborderons ici un sous-ensemble de ces méthodes, en utilisant la notation introduite par les auteurs dans le livre.
Type 0 : Conserver l'original
Cette méthode est la plus simple et convient au traitement de tout champ dont le nom est « original » (ou équivalent). Ces valeurs ne peuvent tout simplement pas être modifiées. Si une nouvelle valeur est trouvée, elle est supprimée et la valeur d'origine est conservée.
Type 1 : Remplacer
Cette méthode convient aux modifications liées à des erreurs ou au traitement de domaines pour lesquels l'entreprise n'est pas intéressée par le suivi des changements temporels. La méthode consiste à remplacer la valeur précédente. Les clients qui modifient leur date d'anniversaire en sont un exemple. La date de naissance d'une personne ne peut normalement pas changer. Nous pouvons donc supposer que, si elle change, c'est dû à une faute de frappe. Pour cette raison, nous allons supprimer la date d'anniversaire précédente et conserver toujours la dernière valeur. C'est le contraire de l'approche de type 0.
Type 2 : Ajouter une nouvelle ligne
Ici, nous commençons réellement à suivre les modifications. La méthode de type 2 ajoute une nouvelle ligne à la dimension. Les nouveaux faits seront liés à la nouvelle clé et les anciens resteront liés à l'ancienne clé. Un cas d'utilisation de cette approche serait de changer d'adresse. À des fins d'analyse, nous souhaiterions conserver les informations d'adresse à partir desquelles chaque vente a été effectuée. Dans le cas contraire, nous pourrions assister à des changements dans les mesures, par exemple les délais de livraison, qui ne seraient pas explicables si nous remplacions également l'adresse pour les anciennes ventes (qui serait de type 1).
Dans cette méthode, certains attributs doivent être ajoutés sur chaque ligne de la dimension. Les attributs 1 et 2 sont obligatoires et les autres sont facultatifs :
- Date de début : date à partir de laquelle l'enregistrement est valide
- Date de fin : date jusqu'à laquelle l'enregistrement est valide
- Drapeau actuel : Cela indique l'entrée actuellement active, pour faciliter le filtrage
- Date de modification : date à laquelle la modification a été enregistrée dans l'entrepôt de données, qui peut être différente de la date à laquelle le client a changé d'adresse
- Motif du changement : pour suivre quel attribut d'une dimension a provoqué la création d'une nouvelle ligne.
Type 3 : Ajouter une nouvelle colonne (ou une réalité alternative)
Cette méthode est utile lorsqu'un changement fondamental se produit dans la façon dont un attribut est défini et que l'entreprise souhaite suivre l'attribut dans son ancienne et sa nouvelle définition. Les modifications apportées à la catégorisation des produits à la suite d'une fusion avec une autre société en sont un exemple typique. Un téléviseur pouvait auparavant être classé dans la catégorie « électronique » et dans la catégorie « média » dans la nouvelle entreprise. Les analystes veulent être en mesure de choisir la catégorisation à prendre en compte. Dans ce cas, une nouvelle colonne est ajoutée aux dimensions en mappant l'ancienne valeur à la nouvelle valeur.
Type 4 : Ajouter une mini-dimension
Parfois, dans une dimension, certains attributs changent à des vitesses différentes. Par exemple, dans la dimension client, il peut y avoir l'adresse qui change normalement toutes les quelques années, et le mode de livraison préféré actuel, qui peut changer même tous les jours car il est souvent modifiable d'un simple clic sur un site Web. Le suivi de cet attribut à l'aide de l'approche de type 2 peut entraîner une augmentation rapide du nombre de lignes dans la dimension, ce qui rend les requêtes sur des paramètres à évolution lente moins performantes. La solution consiste à scinder la dimension client en deux, chacune ayant sa propre clé primaire dans la table des faits séparément. L'un suivra les attributs qui changent lentement et l'autre ceux qui changent rapidement.
Type 5 : Ajoutez une mini-dimension et un stabilisateur de type 1
Cette méthode est similaire au type 4, mais elle inclut en outre la clé primaire de la dimension à évolution rapide en tant que clé étrangère vers la table de dimensions « principale », c'est-à-dire la table contenant la dimension à évolution lente. Cela permet de relier directement les deux dimensions sans passer par un tableau de faits. D'autre part, la table de dimensions « principale » ne peut contenir que la version « actuelle » de l'attribut qui évolue rapidement.
Automatisez le tout à l'aide de WhereScape
Tout cela semble compliqué à implémenter en écrivant du SQL explicite ? Il existe une solution pour vous. Heureusement, ces méthodes sont basées sur des règles simples et se prêtent donc facilement à l'automatisation ! Où se trouve Scape est un leader avec 20 ans d'expérience dans l'automatisation des entrepôts de données. Lorsque vous utilisez WhereScape, vous choisissez le type de suivi des modifications que vous souhaitez, et un assistant vous aidera à configurer l'implémentation sans avoir à écrire une seule ligne de code. De plus, cette œuvre est facilement réutilisable pour plusieurs dimensions. Si vous souhaitez vous écarter des règles standard définies par Kimball, il est possible de modifier et de personnaliser le modèle qui génère le code, et d'automatiser ainsi la création de votre propre algorithme de suivi des modifications.
Voyons maintenant comment cela fonctionne. Dans l'exemple suivant, nous supposerons que les données sont déjà chargées dans la base de données cible dans une table par étapes contenant des informations sur les marchés, notamment leur localisation et leurs caractéristiques.
Les tables d'étape sont des tables de travail dans lesquelles des transformations sont effectuées sur les données avant de les charger dans les objets finaux (dimensions ou tables de faits). Les tables d'étapes sont généralement temporaires et tronquées à chaque cycle de charge. Cette table d'étape peut provenir de plusieurs tables sources et implémenter déjà une logique métier complexe. C'est un bon sujet pour un autre article. Pour l'instant, nous allons nous concentrer sur la manière de créer une dimension de type 2 à évolution lente à partir de ce tableau d'étapes.
Il suffit de cliquer sur le type d'élément « Dimension » dans le volet de gauche, puis de faire glisser et déposer le tableau des étapes dans la zone de travail.
Un assistant s'affichera pour vous aider à configurer votre nouvelle dimension.
Tout d'abord, il faut lui donner un nom. Notez que l'assistant propose un nom pour cette table, conformément aux meilleures pratiques en matière d'entrepôt de données : il utilise le nom de la table de stage et remplace « stage » par « dim ». Vous pouvez bien entendu personnaliser la convention de dénomination ainsi que le nom d'une entité unique que vous ne souhaitez pas suivre. De plus, vous pouvez choisir l'endroit où vous souhaitez stocker votre dimension. Par exemple, les entités stockées de manière permanente (sous forme de dimensions) sont généralement stockées dans un emplacement doté de fonctionnalités de sauvegarde plus robustes.
La deuxième fenêtre vous demande quel type de dimensions vous souhaitez créer. Comme vous pouvez le constater, les types 1, 2 et 3 sont possibles. Vous pouvez également choisir d'utiliser des horodatages générés par le système ou des horodatages pilotés par les données. Pour cet exemple, nous allons choisir « Slowly Changing » (Type 2).
La fenêtre suivante vous permettra de documenter entièrement votre dimension, y compris son grain, sa destination et son utilisation. Toutes ces informations apparaîtront dans la documentation produite automatiquement.
Plus important encore, l'assistant créera le code qui gérera les insertions et les mises à jour. La modification du DDL (langage de définition des données) est également possible si nécessaire. Pour personnaliser la procédure de mise à jour, cliquez sur « Reconstruire ».
Dans la fenêtre suivante, vous pouvez choisir « Créer » ou « Créer et charger ». La raison en est qu'il peut s'agir d'une grande table et que le chargement peut prendre beaucoup de temps. Vous pouvez donc facilement décider de ne pas charger les dimensions immédiatement après leur création, mais plus tard, en arrière-plan, via un planificateur.
Dans la fenêtre suivante, il vous est demandé de configurer la clé métier, c'est-à-dire le champ qui identifie un élément métier. Il peut s'agir d'un client, d'un produit ou, dans ce cas, d'un marché. Nous choisirons « market_id ». Au bas de cette fenêtre, vous trouverez une description utile de l'élément que vous êtes en train de modifier.
Nous avons la possibilité de configurer toutes sortes d'options, mais les valeurs par défaut fonctionnent bien dans la plupart des cas d'utilisation. La dernière étape consiste à décider des attributs dont nous voulons suivre les modifications. Vous pouvez le faire dans la section « Détection des modifications ».
Le choix vous appartient à vous et à vos représentants commerciaux. Pour cet exemple, nous allons choisir la population et la zone. Un marché représente un lieu spécifique, de sorte que sa longitude et sa latitude ne changent pas aussi bien que le nom de la ville dans laquelle il se trouve. S'ils changent, cela est probablement dû à une erreur. Nous ne voulons donc pas suivre ce changement dans le temps. D'autre part, la population et la superficie sont mesurées chaque année et, dans les zones en développement rapide, elles peuvent changer rapidement. Et il peut être intéressant de suivre le contexte dans lequel se situaient les anciennes ventes. Nous allons donc suivre l'évolution de ces deux attributs.
Maintenant, nous cliquons sur « OK » et notre dimension est prête.
Notez que quelques champs ont été automatiquement créés. Il s'agit notamment de la clé de substitution numérique à utiliser comme clé étrangère dans la table de faits et de tous les attributs de modification : dates de début et de fin de validité, indicateur actuel, version, heure de première création et heures de dernière mise à jour. Au fur et à mesure de l'évolution de l'entrepôt de données, ces champs se géreront d'eux-mêmes grâce à la procédure de mise à jour prédéfinie que vous avez configurée à l'aide de l'assistant.
Dans la rubrique « Procédures », nous sommes en mesure d'inspecter le code généré et de le modifier si nécessaire. Sous « Modèles », il est également possible de modifier le modèle qui génère le code, de manière à ce que toutes les dimensions futures soient créées avec nos personnalisations.
Les modèles WhereScape sont complets et gèrent non seulement la gestion des entités, mais également la journalisation des événements et des erreurs afin de garder facilement le contrôle de votre entrepôt de données. Soyez assuré que WhereScape offre toujours la possibilité de configurer des modèles manuellement pour couvrir des cas d'utilisation exceptionnels.
Pour terminer cet exemple, nous pouvons cliquer sur la dimension et voir son schéma :
(Comme vous pouvez le voir sur le schéma, la table de stage ne provenait pas directement d'une table source mais il s'agit d'une jointure entre deux tables sources).
Enfin, il est temps de charger les données. Nous pouvons le faire très simplement en créant une tâche à partir du diagramme de flux et en l'exécutant dans le planificateur.
Comme vous pouvez le voir dans le journal des tâches, les tables VILLES et MARCHÉS ont d'abord été chargées à partir de la source, puis la table par étapes a été créée et enfin les dimensions remplies.
Juste à titre de test, essayons à nouveau d'exécuter le même travail.
Comme vous pouvez le constater, cette fois, les 3 premières étapes ont été exécutées de la même manière et le tableau des étapes était rempli. Mais les données étant les mêmes, aucune modification n'a été détectée et aucune mise à jour n'a donc été effectuée sur la table des dimensions.
Pour terminer, essayons de modifier une entrée pour vérifier si nos dimensions fonctionnent. Je vais notamment modifier la population d'une zone de marché. Pour recharger les données, il suffit de cliquer sur « Démarrer la tâche » sur la même tâche que nous venons de lancer pour effectuer une deuxième exécution.
Cette fois, il met à jour une ligne dans dim_markets. Et nous pouvons également vérifier quel est le résultat sur le tableau.
Il existe désormais deux lignes pour Kuhardt avec le même market_id, la clé métier, mais deux dim_markets_key différentes, qui est la clé de substitution créée automatiquement par WhereScape qui sera utilisée pour rejoindre la table de faits. Enfin, ces données incluent également les dates de début et de fin gérées automatiquement et le drapeau actuel pour chaque enregistrement.