Opérations sur la ligne précédente/suivante dans Tableau

Les données se présentent sous toutes leurs formes et il est souvent nécessaire de récupérer des informations à partir de différentes lignes de données pour calculer les indicateurs. Cela peut être réalisé dans Tableau Desktop à l'aide de calculs tabulaires.
Passons en revue un exemple pratique. Nous avons souvent des lignes décrivant des événements dans le temps où l'horodatage de la ligne suivante représente l'heure de fin de la ligne précédente. Nous pouvons imaginer un contexte de course dans lequel un horodatage est collecté lorsqu'un coureur atteint certains points de contrôle.
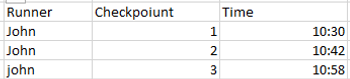
Pour suivre, vous pouvez trouver les fichiers sources sur ce lien, ainsi que la solution des problèmes proposés.
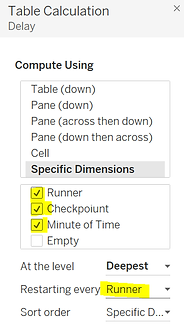
Si nous voulons calculer l'intervalle de temps entre deux points de contrôle dans Tableau Desktop, nous pouvons le faire avec le calcul de table suivant :

Nous devons effectuer ce calcul le long du point de contrôle et le redémarrer à chaque coureur.
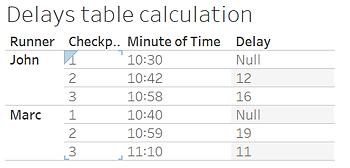
Le résultat est le suivant : exactement ce dont nous avions besoin !
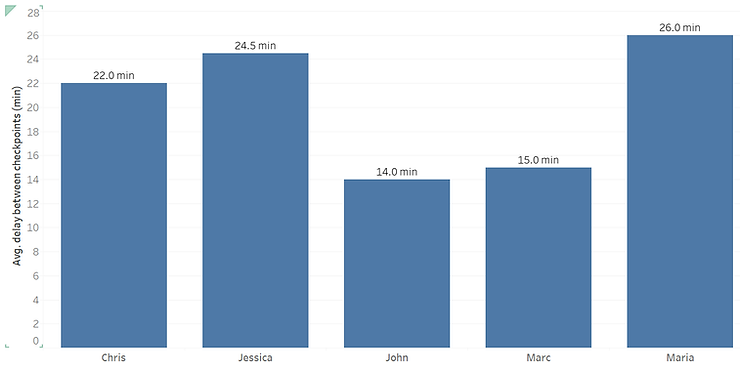
Et si nous devions calculer le délai moyen par coureur et produire le graphique suivant, qui montre le temps moyen passé par un coureur entre les points de contrôle.
Nous pouvons essayer d'utiliser la fonction WINDOW_AVG, mais comme ce sont tous des calculs de table, nous devons avoir le point de contrôle dans la vue pour calculer le long de celui-ci. Le fait d'avoir un point de contrôle dans la vue ne produit pas le graphique que nous cherchons à créer. Une autre solution pourrait consister à utiliser des calculs LoD assez complexes, mais n'oubliez pas que les LOD pénalisent les performances des grands ensembles de données.
Bonne nouvelle ! Tableau propose un outil de préparation des données qui pourrait nous aider à résoudre ce problème et nous permettre de Préparationsont les données dans un format qui facilitera la visualisation requise dans Tableau Desktop. Un autre avantage est que cette préparation des données peut être normalisée pour chaque utilisateur de la source de données préparée.
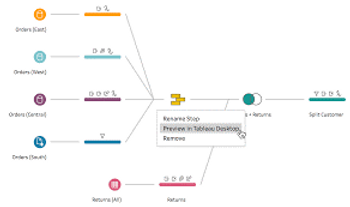
Cet article explique comment récupérer des informations pour d'autres lignes dans Tableau Prep.
Analyse approfondie de la solution
Afin de calculer la durée, nous allons joindre le tableau à lui-même, pour ajouter sur chaque ligne, l'horodatage de la suivante. Pour ce faire, nous devons ajouter une clé qui nous permet de joindre chaque ligne à la suivante.
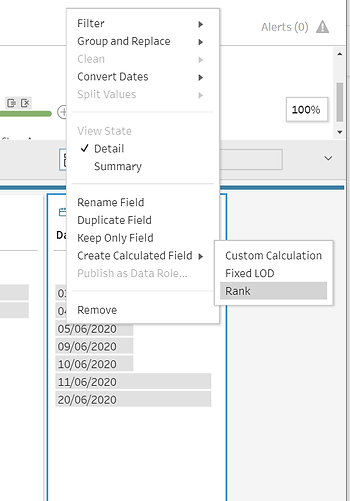
Nous pouvons obtenir ce que nous voulons en utilisant la fonction rank, qui peut être utilisée en cliquant sur la date de saisie et en sélectionnant « Créer un champ calculé -> Classement ».
La fenêtre suivante s'ouvre dans laquelle nous pouvons choisir :
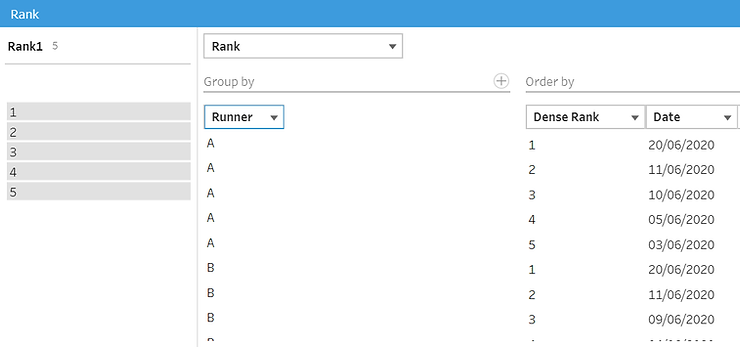
- Le type de regroupement, le cas échéant. Par exemple, si chaque ligne est une mesure du temps d'un coureur et que nous avons plusieurs coureurs dans le même tableau, nous ne voulons pas mélanger les données des différents coureurs. Nous devons donc regrouper par coureur.
- Type de classement. Il doit s'agir d'un « rang dense » pour éviter les cas où un coureur a deux fois le même horodatage, ce qui entraînerait une duplication des lignes si les deux lignes recevaient le même rang. Le rang dense donne plutôt un rang différent à chaque ligne. Si leur rang est le même, cela augmente simplement le rang dans l'ordre dans lequel les lignes apparaissent.
Et voilà ! Nous avons maintenant notre clé, ou presque. Nous devons joindre chaque ligne avec ensuite, nous allons donc créer un champ de calcul d'ordre dans lequel nous ajouterons simplement 1 au rang.
Nous allons maintenant créer le flux de préparation. Tout d'abord, dupliquez les données en créant deux étapes de nettoyage sur différentes branches. Une branche représentera les données de base, la seconde les dates de fin. Dans cette dernière branche, nous pouvons supprimer tous les champs sauf l'horodatage, la clé et le calcul « rang + 1 »
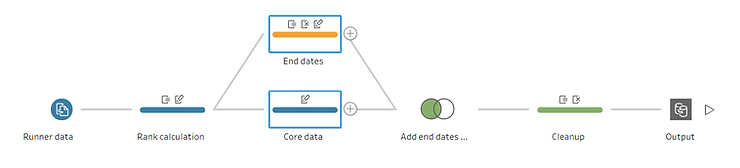
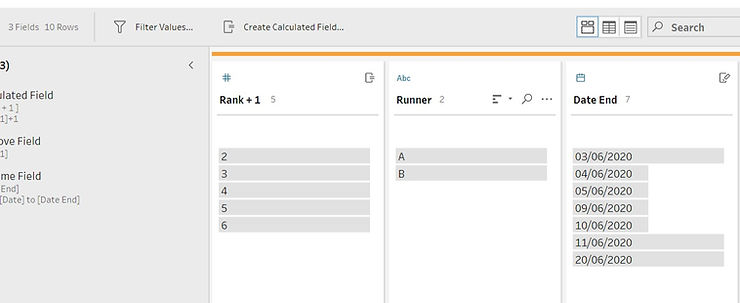
Comme dans la branche « Dates de fin » nous avons conservé « Rang + 1 », nous pouvons renommer la date de cette branche « Date de fin » car il s'agit de l'horodatage de la ligne « suivante », à savoir fin horodatage. Une solution similaire aurait pu être obtenue en conservant « Rang » au lieu de « Rang + 1 » et en renommant la date correspondante « Date de début ».
Enfin, nous allons joindre les deux branches sur la clé de regroupement et « rang = rang + 1 ». Le type de jointure que nous avons choisi nécessite une attention particulière : il peut s'agir d'une jointure gauche sur les données de base ou d'une jointure interne. Si nous choisissons une jointure gauche, nous conserverons toutes les lignes de la première branche, mais la première ligne n'aura aucune durée car elle n'a pas de date de début. Une jointure gauche est généralement ce dont nous avons besoin. Il se peut que nous souhaitions ne conserver que les lignes ayant une durée. Dans ce cas, nous choisirons une jointure interne et la première ligne sera perdue pour chaque coureur.
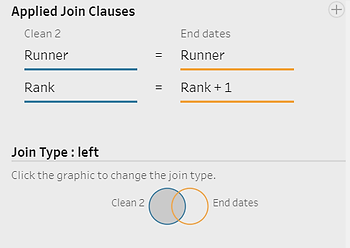
L'ensemble de données obtenu contient une date de début et une date de fin sur la même ligne. Nous pouvons maintenant simplement calculer la différence à l'aide d'un DATEDIFF et publier le résultat sous forme de source de données de tableau ou de fichier plat.
Nous sommes maintenant prêts à connecter la source de données produite à Tableau Desktop et à afficher le délai moyen par coureur, selon les besoins !
Les données se présentent sous toutes leurs formes et il est souvent nécessaire de récupérer des informations à partir de différentes lignes de données pour calculer les indicateurs. Cela peut être réalisé dans Tableau Desktop à l'aide de calculs tabulaires.
Passons en revue un exemple pratique. Nous avons souvent des lignes décrivant des événements dans le temps où l'horodatage de la ligne suivante représente l'heure de fin de la ligne précédente. Nous pouvons imaginer un contexte de course dans lequel un horodatage est collecté lorsqu'un coureur atteint certains points de contrôle.
Pour suivre, vous pouvez trouver les fichiers sources sur ce lien, ainsi que la solution des problèmes proposés.
Si nous voulons calculer l'intervalle de temps entre deux points de contrôle dans Tableau Desktop, nous pouvons le faire avec le calcul de table suivant :
Nous devons effectuer ce calcul le long du point de contrôle et le redémarrer à chaque coureur.
Le résultat est le suivant : exactement ce dont nous avions besoin !
Et si nous devions calculer le délai moyen par coureur et produire le graphique suivant, qui montre le temps moyen passé par un coureur entre les points de contrôle.
Nous pouvons essayer d'utiliser la fonction WINDOW_AVG, mais comme ce sont tous des calculs de table, nous devons avoir le point de contrôle dans la vue pour calculer le long de celui-ci. Le fait d'avoir un point de contrôle dans la vue ne produit pas le graphique que nous cherchons à créer. Une autre solution pourrait consister à utiliser des calculs LoD assez complexes, mais n'oubliez pas que les LOD pénalisent les performances des grands ensembles de données.
Bonne nouvelle ! Tableau propose un outil de préparation des données qui pourrait nous aider à résoudre ce problème et nous permettre de Préparationsont les données dans un format qui facilitera la visualisation requise dans Tableau Desktop. Un autre avantage est que cette préparation des données peut être normalisée pour chaque utilisateur de la source de données préparée.
Cet article explique comment récupérer des informations pour d'autres lignes dans Tableau Prep.
Analyse approfondie de la solution
Afin de calculer la durée, nous allons joindre le tableau à lui-même, pour ajouter sur chaque ligne, l'horodatage de la suivante. Pour ce faire, nous devons ajouter une clé qui nous permet de joindre chaque ligne à la suivante.
Nous pouvons obtenir ce que nous voulons en utilisant la fonction rank, qui peut être utilisée en cliquant sur la date de saisie et en sélectionnant « Créer un champ calculé -> Classement ».
La fenêtre suivante s'ouvre dans laquelle nous pouvons choisir :
- Le type de regroupement, le cas échéant. Par exemple, si chaque ligne est une mesure du temps d'un coureur et que nous avons plusieurs coureurs dans le même tableau, nous ne voulons pas mélanger les données des différents coureurs. Nous devons donc regrouper par coureur.
- Type de classement. Il doit s'agir d'un « rang dense » pour éviter les cas où un coureur a deux fois le même horodatage, ce qui entraînerait une duplication des lignes si les deux lignes recevaient le même rang. Le rang dense donne plutôt un rang différent à chaque ligne. Si leur rang est le même, cela augmente simplement le rang dans l'ordre dans lequel les lignes apparaissent.
Et voilà ! Nous avons maintenant notre clé, ou presque. Nous devons joindre chaque ligne avec ensuite, nous allons donc créer un champ de calcul d'ordre dans lequel nous ajouterons simplement 1 au rang.
Nous allons maintenant créer le flux de préparation. Tout d'abord, dupliquez les données en créant deux étapes de nettoyage sur différentes branches. Une branche représentera les données de base, la seconde les dates de fin. Dans cette dernière branche, nous pouvons supprimer tous les champs sauf l'horodatage, la clé et le calcul « rang + 1 »
Comme dans la branche « Dates de fin » nous avons conservé « Rang + 1 », nous pouvons renommer la date de cette branche « Date de fin » car il s'agit de l'horodatage de la ligne « suivante », à savoir fin horodatage. Une solution similaire aurait pu être obtenue en conservant « Rang » au lieu de « Rang + 1 » et en renommant la date correspondante « Date de début ».
Enfin, nous allons joindre les deux branches sur la clé de regroupement et « rang = rang + 1 ». Le type de jointure que nous avons choisi nécessite une attention particulière : il peut s'agir d'une jointure gauche sur les données de base ou d'une jointure interne. Si nous choisissons une jointure gauche, nous conserverons toutes les lignes de la première branche, mais la première ligne n'aura aucune durée car elle n'a pas de date de début. Une jointure gauche est généralement ce dont nous avons besoin. Il se peut que nous souhaitions ne conserver que les lignes ayant une durée. Dans ce cas, nous choisirons une jointure interne et la première ligne sera perdue pour chaque coureur.
L'ensemble de données obtenu contient une date de début et une date de fin sur la même ligne. Nous pouvons maintenant simplement calculer la différence à l'aide d'un DATEDIFF et publier le résultat sous forme de source de données de tableau ou de fichier plat.
Nous sommes maintenant prêts à connecter la source de données produite à Tableau Desktop et à afficher le délai moyen par coureur, selon les besoins !