Optimisation des performances de Tableau Dashboard

Contexte
L'optimisation des performances est une préoccupation très courante dans divers contextes. Dans le contexte des tableaux de bord Tableau, cela concerne principalement le temps nécessaire au chargement initial du tableau de bord ainsi que le temps passé à attendre lors de l'interaction avec le tableau de bord à l'aide de filtres, de surligneurs, etc. L'un de nos clients possédant des centaines de tableaux de bord, une grande quantité de flux Tableau Prep et divers sites Tableau Server rencontrait de graves problèmes de performances à tous les niveaux. Les flux de préparation prenaient tellement de temps à s'exécuter que les ressources du serveur commençaient à atteindre leurs limites et de nombreux tableaux de bord étaient si lents qu'ils devenaient pratiquement impossibles à utiliser pour l'entreprise. Afin de commencer à résoudre ces problèmes, l'aide d'Argusa a été sollicitée pour optimiser un tableau de bord spécifique et présenter les meilleures pratiques générales et des conseils sur le sujet.
Problème
Le tableau de bord consistait essentiellement en une liste d'actifs avec leurs indicateurs de performance associés, avec des visualisations des 20 actifs les plus performants ou les moins performants. Différents filtres et paramètres ont permis de se concentrer sur des dimensions ou des métriques spécifiques. La source de données était composée de plus de 200 champs, dont près d'un tiers étaient des champs calculés, et de plus de 4 millions de lignes. Il y avait beaucoup de duplication en raison de la manière dont la sécurité était mise en œuvre, étant donné que les données étaient sensibles et pouvaient être consultées par différents types de public. Nous y reviendrons plus tard.
Pour mesurer les performances du tableau de bord et disposer d'une méthode systématique pour effectuer une comparaison avant et après nos modifications, nous avons utilisé la fonctionnalité pratique de Tableau appelée Enregistreur de performance.
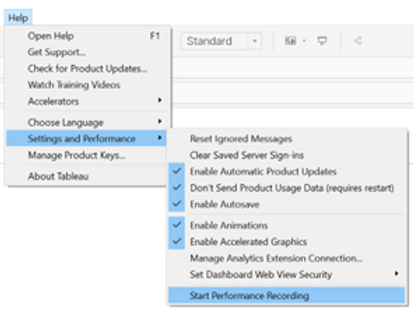
Nous avons mesuré le temps nécessaire pour modifier deux filtres et un paramètre ainsi que le temps de chargement initial du tableau de bord. Le résultat a été qu'il a fallu 2 min 38 s pour la charge initiale et années 78 pour appliquer les modifications. De toute évidence, ce n'est pas le tableau de bord le plus agréable à utiliser.
Solution
Bien que de nombreux facteurs puissent avoir une incidence sur les performances d'un tableau de bord, ils peuvent être regroupés en deux groupes principaux.
- Disposition: disposition des éléments d'un tableau de bord et manière dont les visualisations sous-jacentes sont construites.
- Requête: La demande de données et la manière dont la source de données est créée.
Optimisation de la disposition
Afin d'illustrer le cas, nous avons créé ci-après un tableau de bord fictif avec une structure similaire à celle du client. L'idée est simplement une liste des 20 meilleurs produits présentant le ratio de profit le plus élevé, avec la possibilité de filtrer en fonction du type de produit ou de la valeur de vente minimale.
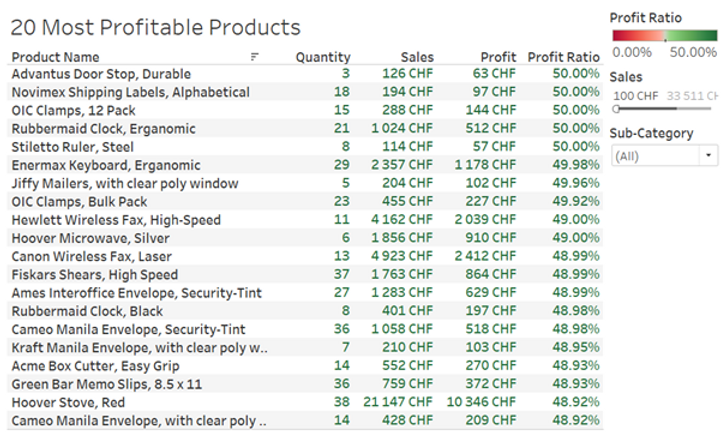
Examinons maintenant en détail la façon dont la visualisation sous-jacente a été construite.
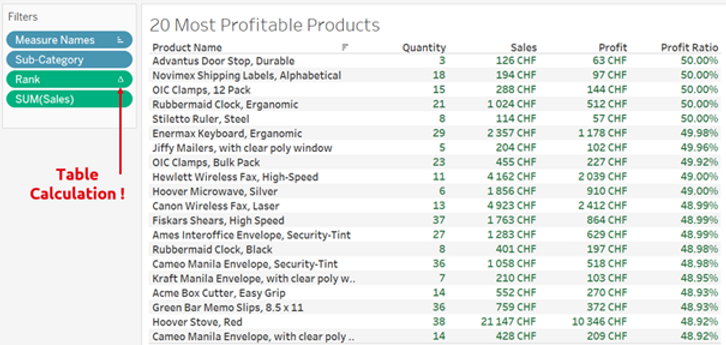
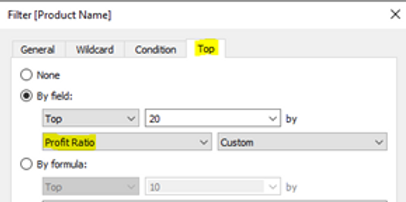
Comme nous pouvons le constater, afin d'afficher les 20 produits les plus rentables, un calcul du tableau RANK () (comme le montre le symbole Δ) a été utilisé. Cela signifie que Tableau doit d'abord charger tous les produits, qui dans le cas de notre client correspondaient à environ 40 000 lignes, afin d'appliquer ensuite un calcul de classement qui est ensuite utilisé comme filtre pour ne conserver que les 20 premières. Le même résultat peut être obtenu de manière plus intelligente, comme indiqué ci-dessous.
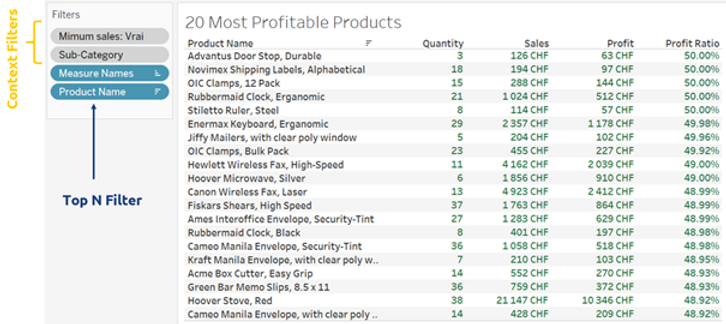
Ici, nous avons utilisé des filtres contextuels sur les catégories et des ventes minimales afin de préfiltrer les données. De plus, nous avons utilisé un filtre Top N sur les produits. Il s'agit d'une méthode beaucoup plus efficace pour interroger les données sous-jacentes que les calculs de table, qui sont toujours appliqués en dernier et nécessitent donc de charger la table entière avant de la filtrer.
Une autre petite astuce intéressante consiste à utiliser l'option « Afficher le bouton d'application » sur les filtres à valeurs multiples du tableau de bord, car cela permet d'envoyer une seule demande lors de l'exécution d'une option de sélection multiple.
L'enregistrement des performances du tableau de bord du client avant et après les modifications est présenté ci-dessous.
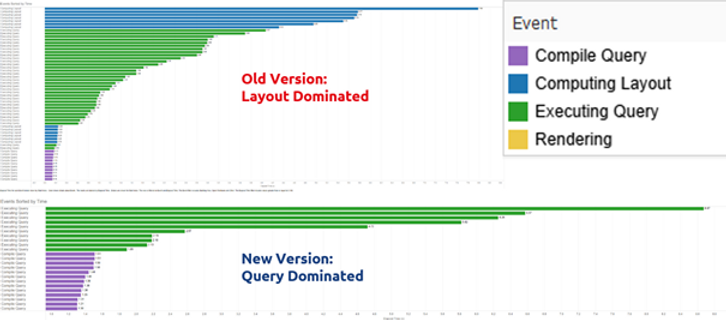
Comme on peut le voir, dans la version originale (en haut), le temps était principalement consacré à la mise en page tandis que dans la nouvelle version (en bas), le temps était consacré à la requête. Le temps dû à la mise en page était 41,4 s avant et 1,9 s après. Dans l'ensemble, le temps de chargement initial est passé de 2 min 38 s pour 2 min 18 s alors que le temps d'interaction passait de années 78 pour années 30. C'est assez impressionnant car le modèle de données et la source de données sous-jacents ont n'a pas été modifié quoi que ce soit. Nous voyons donc qu'il vaut la peine de réfléchir à la manière dont une visualisation est construite et de ne pas simplement utiliser la première solution qui fonctionne.
Recommandations générales pour la mise en page
Voici une liste de recommandations générales pour améliorer les performances grâce au calcul de la mise en page.
- Les calculs de table sont généralement très lents car ils sont appliqués à la vue résultante. Ils ne doivent être utilisés qu'en dernier recours s'il n'est pas possible d'obtenir les résultats souhaités par d'autres moyens.
- Dans la mesure du possible, il est préférable d'éviter les calculs du niveau de détail (LOD) au profit d'agrégations standard, car les premiers sont plus lents à calculer.
- L'utilisation intelligente des filtres contextuels permet de réduire la quantité de données à traiter ultérieurement.
- En cas de données dupliquées, utilisez MIN/MAX au lieu d'AVG.
- Minimisez le nombre d'éléments dans une vue/un tableau de bord.
- Utilisez le bouton « Afficher le bouton Appliquer » sur les filtres à sélection multiple.
Optimisation des requêtes
La plupart du temps, les performances dépendent principalement de la requête sous-jacente. Cela est tout à fait normal, car plus la source de données est grande, plus l'interrogation sera lente. Il est donc recommandé de concevoir la source de données selon une approche minimaliste. L'objectif doit être de créer une source de données avec le moins d'enregistrements/lignes et de dimensions, y compris des champs calculés, capable de fournir le comportement et les fonctionnalités souhaités sur le tableau de bord.
Recommandations générales pour la requête
Voici une liste de recommandations générales visant à améliorer les performances dues à la requête.
- Si possible, créez une source de données contenant uniquement les champs obligatoires. Sinon, masquez les champs non utilisés.
- Évitez d'utiliser du SQL personnalisé car cela limite la capacité de Tableau à optimiser en interne la demande de données. En particulier lorsque des sous-requêtes sont présentes dans la requête SQL.
- Au lieu d'utiliser des champs calculés factices par exemple pour modifier l'affichage du nom d'un champ

par exemple [Nom du client] = [People (People)], vous pouvez à la place :
- Renommez le champ.
- Utilisez un alias.
- Double-cliquez sur le champ

et ajoutez «//<alias>»

avant le nom du champ et appuyez sur Shift+Enter.
Cela permet de conserver le nom d'origine du champ dans le volet de données.

- Évitez les expressions LOD inutiles.
- Pour les jointures, la hiérarchie des performances est la suivante : INTÉRIEUR > GAUCHE/DROITE > PLEIN.
- Pour les types de données, la hiérarchie des performances est la suivante : Boolean > Float > Date > String.
- Préférez l'utilisation de tables de base de données plutôt que de vues.
Refonte du modèle de données
Dans le cas de notre client, le principal problème provenait du modèle de source de données qui est reproduit schématiquement ci-dessous.

Le modèle est relativement complexe, mais surtout, il ne dépend que de SQL personnalisé requêtes de vues. Il existe différents extérieur complet des jointures qui introduisent de nombreuses lignes dupliquées. La source de données qui en résulte est composée de 148 natif + 64 champs calculés et plus de 4 millions lignes, dont beaucoup sont des doublons. La source de données a été conçue de cette manière pour mettre en œuvre la sécurité et éviter que la mauvaise personne n'accède à des données confidentielles par exemple en fonction de sa localisation. La sécurité a été mise en œuvre via un champ calculé. Cela pose en fait divers problèmes :
- La gouvernance des données est mal définie.
- Difficile à mettre en œuvre et à gérer lorsqu'il s'agit de divers classeurs.
- Difficile de comprendre, de classer et de faire évoluer les différentes règles d'accès.
- Nécessite de dupliquer les données en utilisant des jointures externes complètes, puis en utilisant des expressions LOD pour effectuer l'agrégation correcte.
Afin de résoudre ces différents problèmes, Argusa a complètement repensé le modèle de données. Le nouveau modèle est illustré ci-dessous.

Où les trois composants sont tables calculé dans base de données. Ils sont liés à l'aide de interne rejoint.
La table Règle de sécurité indique quelle règle d'accès est appliquée pour chaque utilisateur du tableau de bord.

La table Lien entre la règle et le produit, comme son nom l'indique, associe une règle de sécurité donnée à l'identifiant des produits correspondants auxquels il est possible d'accéder.

La table Données sur le produit contient les données réelles qui présentent un intérêt et constitue une version retravaillée du modèle précédent.
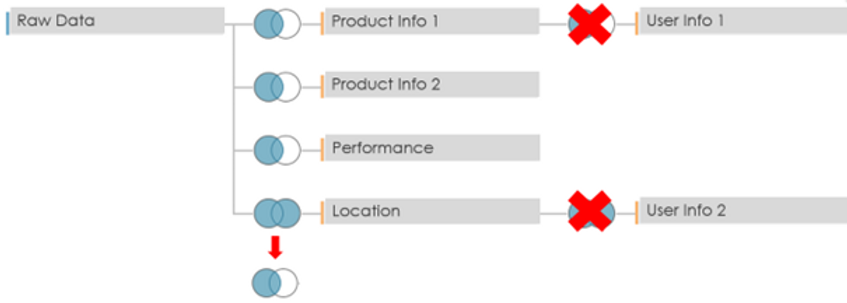
Les jointures sur les tableaux d'informations utilisateur ne sont plus nécessaires et la jointure sur le Lieu la table est passée d'une jointure extérieure complète à une jointure gauche.
Le modèle obtenu contient uniquement 35 natif + 43 champs calculés. De plus, le nombre de lignes de données auxquelles il faut accéder est d'au plus 400 km, en fonction des droits d'accès, soit 10 fois moins. Ce nouveau modèle interroge uniquement les produits concernés par les droits d'accès de l'utilisateur du tableau de bord. De plus, les règles d'accès sont désormais centralisées dans la base de données et peuvent potentiellement être dynamiques. Le test de performance initial est réitéré à l'aide d'un utilisateur ayant accès à l'ensemble de données complet. Les résultats sont qu'il faut années 13 pour effectuer le chargement initial et années 20 pour appliquer toutes les modifications. Comme on peut le constater, l'amélioration du modèle de données a eu de loin l'impact le plus important sur les performances. La comparaison des performances globales entre les différentes versions du tableau de bord est présentée dans le tableau suivant.

Conclusion
Il y a plusieurs éléments à prendre en compte lors de la conception d'un tableau de bord pour en tirer le meilleur parti pour votre argent. Le simple fait de choisir la mise en page adéquate pour une visualisation peut déjà avoir un impact significatif. Cependant, pour tirer le meilleur parti des performances de votre tableau de bord, il est essentiel de concevoir votre modèle de données de manière à conserver un minimum de données.
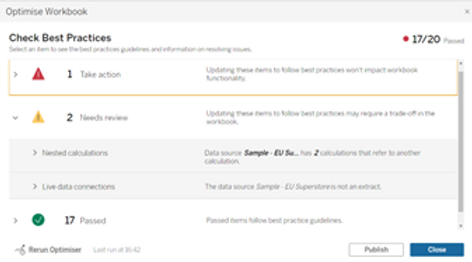
Pour terminer, notez qu'à partir de la version 2022.1, Tableau a introduit le Optimiseur de classeurs qui passe en revue l'ensemble du manuel et compare sa conception aux directives relatives aux meilleures pratiques. Certaines recommandations doivent être prises avec précaution car elles ne sont pas toujours applicables, mais il est généralement conseillé de les exécuter de temps en temps et de vérifier s'il existe quelque chose qui pourrait être fait pour améliorer facilement les performances du tableau de bord.
Contexte
L'optimisation des performances est une préoccupation très courante dans divers contextes. Dans le contexte des tableaux de bord Tableau, cela concerne principalement le temps nécessaire au chargement initial du tableau de bord ainsi que le temps passé à attendre lors de l'interaction avec le tableau de bord à l'aide de filtres, de surligneurs, etc. L'un de nos clients possédant des centaines de tableaux de bord, une grande quantité de flux Tableau Prep et divers sites Tableau Server rencontrait de graves problèmes de performances à tous les niveaux. Les flux de préparation prenaient tellement de temps à s'exécuter que les ressources du serveur commençaient à atteindre leurs limites et de nombreux tableaux de bord étaient si lents qu'ils devenaient pratiquement impossibles à utiliser pour l'entreprise. Afin de commencer à résoudre ces problèmes, l'aide d'Argusa a été sollicitée pour optimiser un tableau de bord spécifique et présenter les meilleures pratiques générales et des conseils sur le sujet.
Problème
Le tableau de bord consistait essentiellement en une liste d'actifs avec leurs indicateurs de performance associés, avec des visualisations des 20 actifs les plus performants ou les moins performants. Différents filtres et paramètres ont permis de se concentrer sur des dimensions ou des métriques spécifiques. La source de données était composée de plus de 200 champs, dont près d'un tiers étaient des champs calculés, et de plus de 4 millions de lignes. Il y avait beaucoup de duplication en raison de la manière dont la sécurité était mise en œuvre, étant donné que les données étaient sensibles et pouvaient être consultées par différents types de public. Nous y reviendrons plus tard.
Pour mesurer les performances du tableau de bord et disposer d'une méthode systématique pour effectuer une comparaison avant et après nos modifications, nous avons utilisé la fonctionnalité pratique de Tableau appelée Enregistreur de performance.
Nous avons mesuré le temps nécessaire pour modifier deux filtres et un paramètre ainsi que le temps de chargement initial du tableau de bord. Le résultat a été qu'il a fallu 2 min 38 s pour la charge initiale et années 78 pour appliquer les modifications. De toute évidence, ce n'est pas le tableau de bord le plus agréable à utiliser.
Solution
Bien que de nombreux facteurs puissent avoir une incidence sur les performances d'un tableau de bord, ils peuvent être regroupés en deux groupes principaux.
- Disposition: disposition des éléments d'un tableau de bord et manière dont les visualisations sous-jacentes sont construites.
- Requête: La demande de données et la manière dont la source de données est créée.
Optimisation de la disposition
Afin d'illustrer le cas, nous avons créé ci-après un tableau de bord fictif avec une structure similaire à celle du client. L'idée est simplement une liste des 20 meilleurs produits présentant le ratio de profit le plus élevé, avec la possibilité de filtrer en fonction du type de produit ou de la valeur de vente minimale.
Examinons maintenant en détail la façon dont la visualisation sous-jacente a été construite.
Comme nous pouvons le constater, afin d'afficher les 20 produits les plus rentables, un calcul du tableau RANK () (comme le montre le symbole Δ) a été utilisé. Cela signifie que Tableau doit d'abord charger tous les produits, qui dans le cas de notre client correspondaient à environ 40 000 lignes, afin d'appliquer ensuite un calcul de classement qui est ensuite utilisé comme filtre pour ne conserver que les 20 premières. Le même résultat peut être obtenu de manière plus intelligente, comme indiqué ci-dessous.
Ici, nous avons utilisé des filtres contextuels sur les catégories et des ventes minimales afin de préfiltrer les données. De plus, nous avons utilisé un filtre Top N sur les produits. Il s'agit d'une méthode beaucoup plus efficace pour interroger les données sous-jacentes que les calculs de table, qui sont toujours appliqués en dernier et nécessitent donc de charger la table entière avant de la filtrer.
Une autre petite astuce intéressante consiste à utiliser l'option « Afficher le bouton d'application » sur les filtres à valeurs multiples du tableau de bord, car cela permet d'envoyer une seule demande lors de l'exécution d'une option de sélection multiple.
L'enregistrement des performances du tableau de bord du client avant et après les modifications est présenté ci-dessous.
Comme on peut le voir, dans la version originale (en haut), le temps était principalement consacré à la mise en page tandis que dans la nouvelle version (en bas), le temps était consacré à la requête. Le temps dû à la mise en page était 41,4 s avant et 1,9 s après. Dans l'ensemble, le temps de chargement initial est passé de 2 min 38 s pour 2 min 18 s alors que le temps d'interaction passait de années 78 pour années 30. C'est assez impressionnant car le modèle de données et la source de données sous-jacents ont n'a pas été modifié quoi que ce soit. Nous voyons donc qu'il vaut la peine de réfléchir à la manière dont une visualisation est construite et de ne pas simplement utiliser la première solution qui fonctionne.
Recommandations générales pour la mise en page
Voici une liste de recommandations générales pour améliorer les performances grâce au calcul de la mise en page.
- Les calculs de table sont généralement très lents car ils sont appliqués à la vue résultante. Ils ne doivent être utilisés qu'en dernier recours s'il n'est pas possible d'obtenir les résultats souhaités par d'autres moyens.
- Dans la mesure du possible, il est préférable d'éviter les calculs du niveau de détail (LOD) au profit d'agrégations standard, car les premiers sont plus lents à calculer.
- L'utilisation intelligente des filtres contextuels permet de réduire la quantité de données à traiter ultérieurement.
- En cas de données dupliquées, utilisez MIN/MAX au lieu d'AVG.
- Minimisez le nombre d'éléments dans une vue/un tableau de bord.
- Utilisez le bouton « Afficher le bouton Appliquer » sur les filtres à sélection multiple.
Optimisation des requêtes
La plupart du temps, les performances dépendent principalement de la requête sous-jacente. Cela est tout à fait normal, car plus la source de données est grande, plus l'interrogation sera lente. Il est donc recommandé de concevoir la source de données selon une approche minimaliste. L'objectif doit être de créer une source de données avec le moins d'enregistrements/lignes et de dimensions, y compris des champs calculés, capable de fournir le comportement et les fonctionnalités souhaités sur le tableau de bord.
Recommandations générales pour la requête
Voici une liste de recommandations générales visant à améliorer les performances dues à la requête.
- Si possible, créez une source de données contenant uniquement les champs obligatoires. Sinon, masquez les champs non utilisés.
- Évitez d'utiliser du SQL personnalisé car cela limite la capacité de Tableau à optimiser en interne la demande de données. En particulier lorsque des sous-requêtes sont présentes dans la requête SQL.
- Au lieu d'utiliser des champs calculés factices par exemple pour modifier l'affichage du nom d'un champ
par exemple [Nom du client] = [People (People)], vous pouvez à la place :
- Renommez le champ.
- Utilisez un alias.
- Double-cliquez sur le champ
et ajoutez «//<alias>»
avant le nom du champ et appuyez sur Shift+Enter.
Cela permet de conserver le nom d'origine du champ dans le volet de données.
- Évitez les expressions LOD inutiles.
- Pour les jointures, la hiérarchie des performances est la suivante : INTÉRIEUR > GAUCHE/DROITE > PLEIN.
- Pour les types de données, la hiérarchie des performances est la suivante : Boolean > Float > Date > String.
- Préférez l'utilisation de tables de base de données plutôt que de vues.
Refonte du modèle de données
Dans le cas de notre client, le principal problème provenait du modèle de source de données qui est reproduit schématiquement ci-dessous.
Le modèle est relativement complexe, mais surtout, il ne dépend que de SQL personnalisé requêtes de vues. Il existe différents extérieur complet des jointures qui introduisent de nombreuses lignes dupliquées. La source de données qui en résulte est composée de 148 natif + 64 champs calculés et plus de 4 millions lignes, dont beaucoup sont des doublons. La source de données a été conçue de cette manière pour mettre en œuvre la sécurité et éviter que la mauvaise personne n'accède à des données confidentielles par exemple en fonction de sa localisation. La sécurité a été mise en œuvre via un champ calculé. Cela pose en fait divers problèmes :
- La gouvernance des données est mal définie.
- Difficile à mettre en œuvre et à gérer lorsqu'il s'agit de divers classeurs.
- Difficile de comprendre, de classer et de faire évoluer les différentes règles d'accès.
- Nécessite de dupliquer les données en utilisant des jointures externes complètes, puis en utilisant des expressions LOD pour effectuer l'agrégation correcte.
Afin de résoudre ces différents problèmes, Argusa a complètement repensé le modèle de données. Le nouveau modèle est illustré ci-dessous.
Où les trois composants sont tables calculé dans base de données. Ils sont liés à l'aide de interne rejoint.
La table Règle de sécurité indique quelle règle d'accès est appliquée pour chaque utilisateur du tableau de bord.
La table Lien entre la règle et le produit, comme son nom l'indique, associe une règle de sécurité donnée à l'identifiant des produits correspondants auxquels il est possible d'accéder.
La table Données sur le produit contient les données réelles qui présentent un intérêt et constitue une version retravaillée du modèle précédent.
Les jointures sur les tableaux d'informations utilisateur ne sont plus nécessaires et la jointure sur le Lieu la table est passée d'une jointure extérieure complète à une jointure gauche.
Le modèle obtenu contient uniquement 35 natif + 43 champs calculés. De plus, le nombre de lignes de données auxquelles il faut accéder est d'au plus 400 km, en fonction des droits d'accès, soit 10 fois moins. Ce nouveau modèle interroge uniquement les produits concernés par les droits d'accès de l'utilisateur du tableau de bord. De plus, les règles d'accès sont désormais centralisées dans la base de données et peuvent potentiellement être dynamiques. Le test de performance initial est réitéré à l'aide d'un utilisateur ayant accès à l'ensemble de données complet. Les résultats sont qu'il faut années 13 pour effectuer le chargement initial et années 20 pour appliquer toutes les modifications. Comme on peut le constater, l'amélioration du modèle de données a eu de loin l'impact le plus important sur les performances. La comparaison des performances globales entre les différentes versions du tableau de bord est présentée dans le tableau suivant.
Conclusion
Il y a plusieurs éléments à prendre en compte lors de la conception d'un tableau de bord pour en tirer le meilleur parti pour votre argent. Le simple fait de choisir la mise en page adéquate pour une visualisation peut déjà avoir un impact significatif. Cependant, pour tirer le meilleur parti des performances de votre tableau de bord, il est essentiel de concevoir votre modèle de données de manière à conserver un minimum de données.
Pour terminer, notez qu'à partir de la version 2022.1, Tableau a introduit le Optimiseur de classeurs qui passe en revue l'ensemble du manuel et compare sa conception aux directives relatives aux meilleures pratiques. Certaines recommandations doivent être prises avec précaution car elles ne sont pas toujours applicables, mais il est généralement conseillé de les exécuter de temps en temps et de vérifier s'il existe quelque chose qui pourrait être fait pour améliorer facilement les performances du tableau de bord.