Passez de JSON à Insight avec Snowflake

Flocon de neige est une plateforme de données intégrée unique, conçue de A à Z pour le cloud. Son architecture de données partagées multi-clusters brevetée comprend des couches de calcul, de stockage et de services cloud qui évoluent indépendamment, permettant à tout utilisateur de travailler avec n'importe quelle donnée, sans aucune limite d'échelle, de performance ou de flexibilité.


Snowflake prend en charge les entrepôts de données modernes, les lacs de données augmentés, la science des données avancée, le développement intensif d'applications, les échanges de données sécurisés et l'ingénierie des données intégrée, le tout en un seul endroit, permettant aux professionnels des données et de la BI de tirer le meilleur parti de leurs données. Plus important encore, Snowflake est sécurisé et régi par sa conception, et est fourni en tant que service ne nécessitant pratiquement aucune maintenance.
Le cloud de données Snowflake offre des fonctionnalités vraiment puissantes. Par exemple, sa gestion des métadonnées permet le clonage zéro copie et le voyage dans le temps. La couche de calcul peut être étendue et dédimensionnée à tout moment pour gérer des charges de travail complexes et simultanées, et vous ne payez que pour ce que vous utilisez. En outre, le stockage et le calcul sont séparés, ce qui garantit que tout le monde peut accéder aux données sans avoir à se heurter à des problèmes de contentieux.
L'une des fonctionnalités les plus intéressantes de Snowflake est sa prise en charge native des données semi-structurées. Avec Snowflake, il n'est pas nécessaire de mettre en œuvre des systèmes distincts pour traiter les données structurées et semi-structurées, ce qui est crucial à l'heure actuelle du Big Data et de l'IoT. Le processus de chargement d'un fichier CSV ou JSON est identique et fluide. De plus, Snowflake est une plate-forme SQL qui vous permet d'interroger des données structurées et semi-structurées à l'aide de SQL avec des performances similaires, sans avoir besoin d'acquérir de nouvelles compétences en programmation.
Nous allons montrer ici, à l'aide d'un exemple simple, à quel point il est facile de charger, d'interroger et d'analyser des données semi-structurées dans Snowflake. Nous examinerons spécifiquement les données de Twitter. Cela est particulièrement intéressant compte tenu du volume de données produit par Twitter et du fait que le modèle de données de Twitter repose sur des données semi-structurées, les tweets étant généralement codés en JSON.
Suivez-moi
Si vous souhaitez une expérience plus pratique, vous pouvez créer votre propre compte Snowflake et suivre notre exemple en copiant et collant le code. Veuillez visiter Snowflake ici pour vous inscrire à un essai gratuit. Snowflake étant fourni en tant que service, il vous suffit de choisir une édition de Snowflake (nous recommandons Entreprise) et une plateforme/région cloud — AWS, Azure ou GCP (Snowflake étant indépendant du cloud, votre expérience sera similaire quelle que soit la plateforme que vous choisissez).
Nous jouerons avec un jeu de données JSON contenant des tweets capturés lors de la finale de l'UEFA Champions League 2018. Vous pouvez télécharger le fichier JSON - TweetsChampions.json - directement sur votre ordinateur depuis kaggle. En raison des restrictions de taille de fichier, nous utiliserons Snow SQL, le client de ligne de commande de Snowflake, pour charger les données de notre ordinateur dans Snowflake. Pour installer SnowSQL, rendez-vous sur Référentiel de Snowflake.
Chargement
Commençons par mettre les choses en place. Ci-dessous, vous pouvez voir une capture d'écran de l'interface Web de Snowflake. Il s'agit d'un outil extrêmement puissant qui peut être utilisé pour effectuer presque toutes les tâches dans Snowflake. Ici, nous utiliserons spécifiquement les feuilles de travail pour créer et soumettre des requêtes et des opérations SQL. Remarquez comment les résultats SQL apparaissent en bas de la page. N'oubliez pas que la plupart de ces opérations peuvent être exécutées à l'aide d'autres fonctionnalités de l'interface Web qui ne nécessitent pas l'écriture de code SQL.
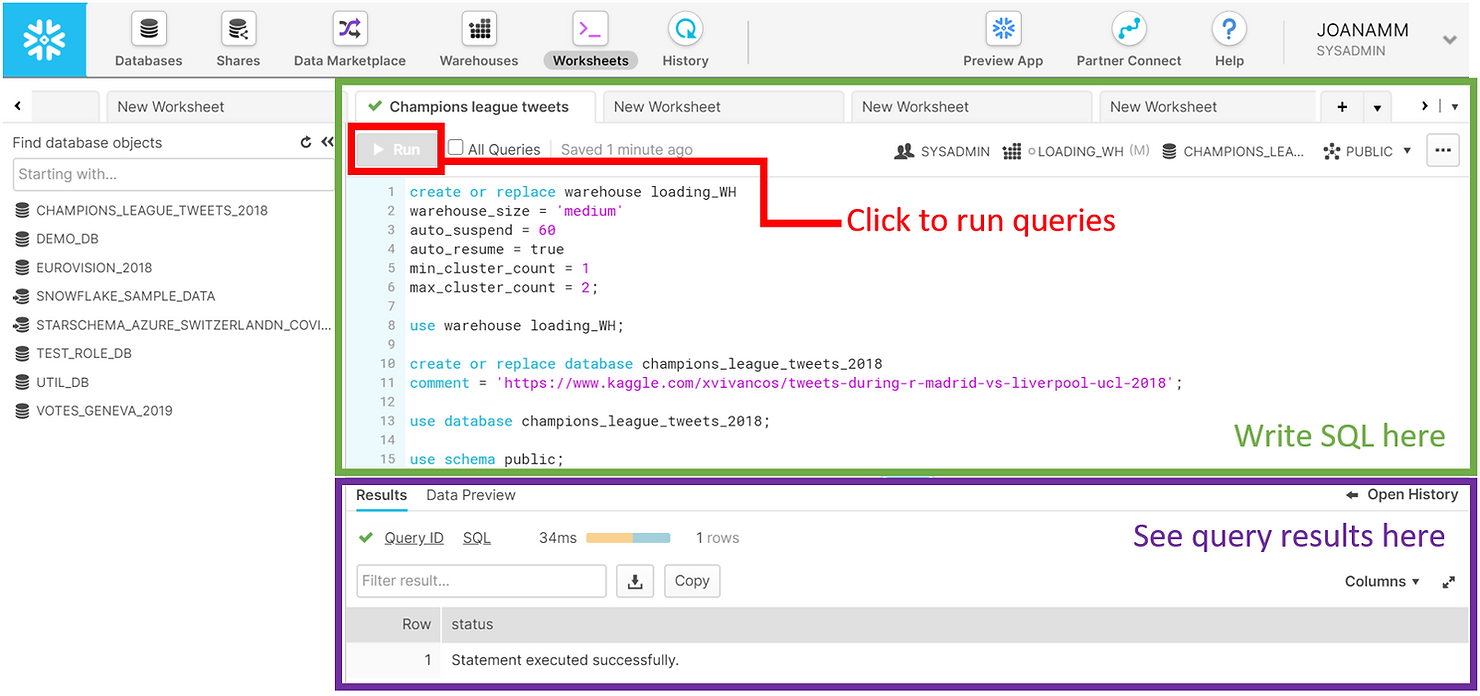
Nous avons commencé par créer un entrepôt de taille moyenne nommé « LOADING_WH ». Les entrepôts de Snowflake sont des unités informatiques virtuelles qui fournissent la puissance de calcul nécessaire à l'exécution des requêtes. Cet entrepôt est constitué d'un cluster de 4 serveurs. Nous avons défini max_cluster_count = 2, ce qui signifie que nous autorisons Snowflake à ajouter automatiquement un autre cluster à l'entrepôt virtuel, afin d'améliorer les performances au cas où plusieurs requêtes seraient soumises simultanément. N'oubliez pas qu'avec Snowflake, vous ne payez pour le calcul que lorsque les entrepôts fonctionnent. Nous avons donc configuré notre LOADING_WH pour qu'il se suspende automatiquement dans les 60 secondes suivant l'inactivité. Pour simplifier notre charge de travail, nous avons également utilisé l'option auto_resume = true, qui lance automatiquement l'entrepôt une fois qu'une requête est soumise. L'opération use warehouse Loading_WH indique que les requêtes soumises dans la feuille de travail utiliseront cet entrepôt pour la puissance de calcul.
CREATE OR REPLACE WAREHOUSE loading_WH
WAREHOUSE_SIZE = 'medium'
AUTO_SUSPEND = 60
AUTO_RESUME = true
MIN_CLUSTER_COUNT = 1
MAX_CLUSTER_COUNT = 2;
USE WAREHOUSE loading_WH;Nous avons également créé une base de données CHAMPIONS_LEAGUE_TWEETS_2018 pour stocker nos données, et nous avons choisi d'utiliser le schéma PUBLIC créé automatiquement dans cette base de données pour plus de simplicité. Nous avons également indiqué que nous utiliserons cette base de données et ces schémas dans le contexte de la feuille de travail.
CREATE OR REPLACE DATABASE champions_league_tweets_2018
COMMENT = 'https://www.kaggle.com/xvivancos/tweets-during-r-madrid-vs-liverpool-ucl-2018';
USE DATABASE champions_league_tweets_2018;
USE SCHEMA public;Pour charger des données dans Snowflake, vous devez généralement suivre les étapes suivantes :
- Créez un format de fichier pour informer Snowflake du type de données que vous allez charger. Snowflake prend en charge le chargement de données structurées (CSV, TSV,...) et semi-structurées (JSON, Avro, ORC, Parquet et XML). Ici, nous avons simplement créé un objet de format de fichier pour les fichiers JSON nommé TWEETS_FILE_FORMAT.
CREATE OR REPLACE FILE_FORMAT tweets_file_format
TYPE = json;- Créez ce que l'on appelle une scène. Une étape est une zone intermédiaire dans laquelle vous allez placer vos fichiers de données avant de les charger dans des tableaux. Les étapes de Snowflake peuvent être internes (elles existent dans Snowflake) ou externes (par exemple, un compartiment AWS S3). Pour cet exemple, nous avons créé un stage interne appelé TWEETS_STAGE. Nous avons également fait référence au format de fichier créé précédemment dans la définition de la scène, car celle-ci contiendra des fichiers JSON. Nous avons ensuite utilisé Snow SQL pour placer notre fichier de données JSON dans cette étape interne. Une fois les données placées dans la scène, vous pouvez répertorier leur contenu. Dans la capture d'écran ci-dessous, vous trouverez le résultat de la commande list. Remarquez comment le fichier JSON est compressé. C'est standard dans Snowflake et cela se fait automatiquement.
CREATE OR REPLACE STAGE tweets_stage
FILE_FORMAT = tweets_file_format;
//use SnowSQL to run the put command and stage local json file
//put file://C:\temp\TweetsChampions.json @tweets_stage;
LIST @tweets_stage;- Créez un tableau contenant vos données. Les données semi-structurées sont notamment chargées dans des tables comportant une seule colonne de type VARIANT. Il s'agit d'un type de données innovant et flexible développé par Snowflake, spécifiquement pour contenir une variété de données semi-structurées.
CREATE OR REPLACE TABLE raw_tweets (tweet variant);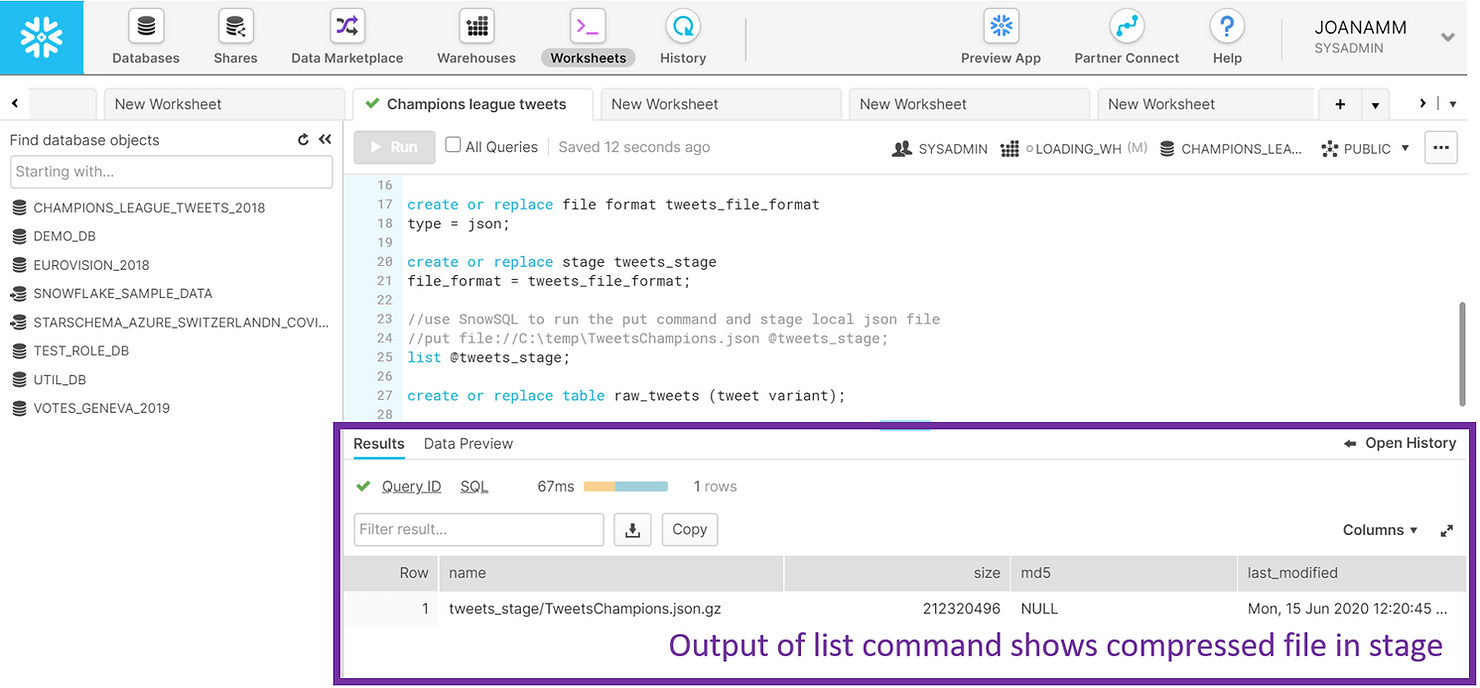
Tout est maintenant en place pour charger les données, et il ne nous reste plus qu'à les copier de la scène dans le tableau. Snowflake sait comment analyser et identifier la structure du fichier JSON. En un peu plus d'une minute, nous avons pu remplir notre tableau RAW_TWEETS d'environ 350 000 lignes, soit 1 ligne par tweet.
COPY INTO raw_tweets FROM @tweets_stage;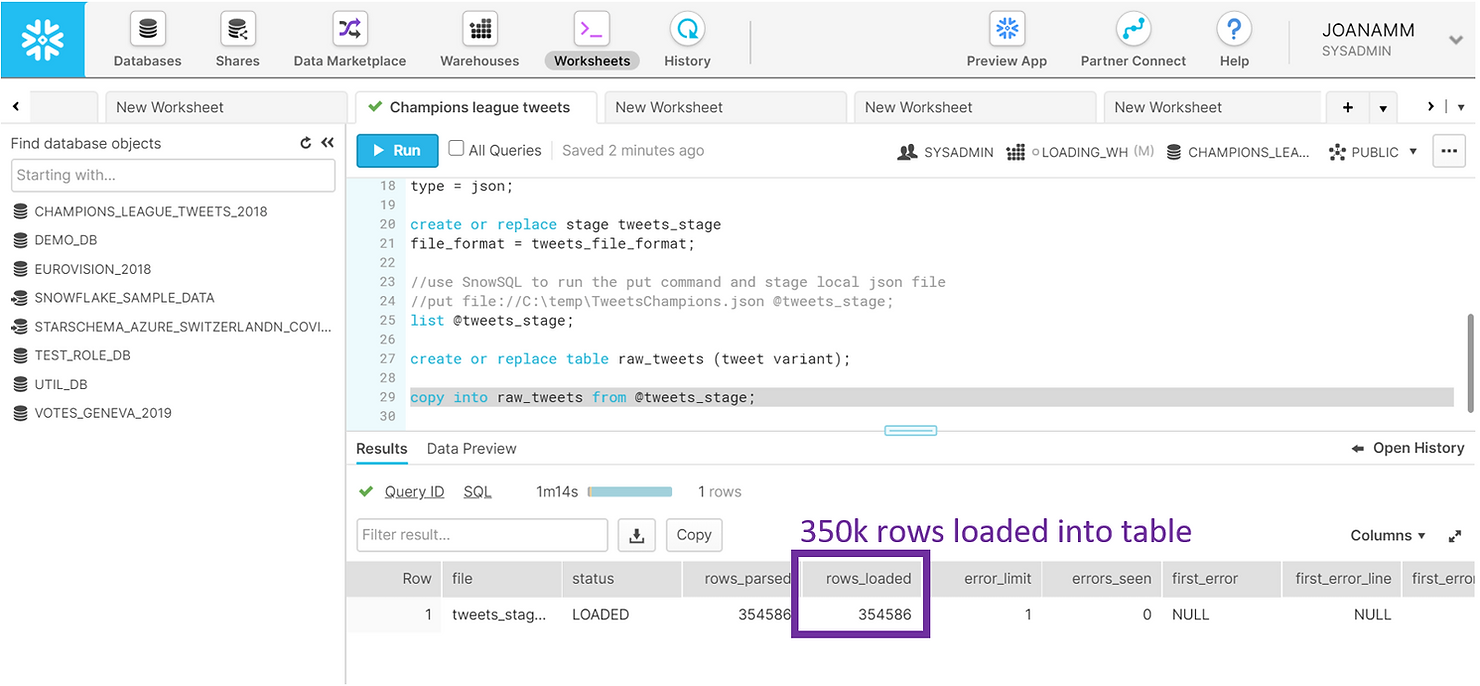
Interrogation
Maintenant que les données ont été chargées, nous pouvons exécuter une simple instruction SELECT sur la table RAW_TWEETS et explorer à quoi ressemble chacune des lignes en cliquant dessus dans le panneau des résultats de l'interface utilisateur Web.
SELECT tweet FROM raw_tweets LIMIT 3;
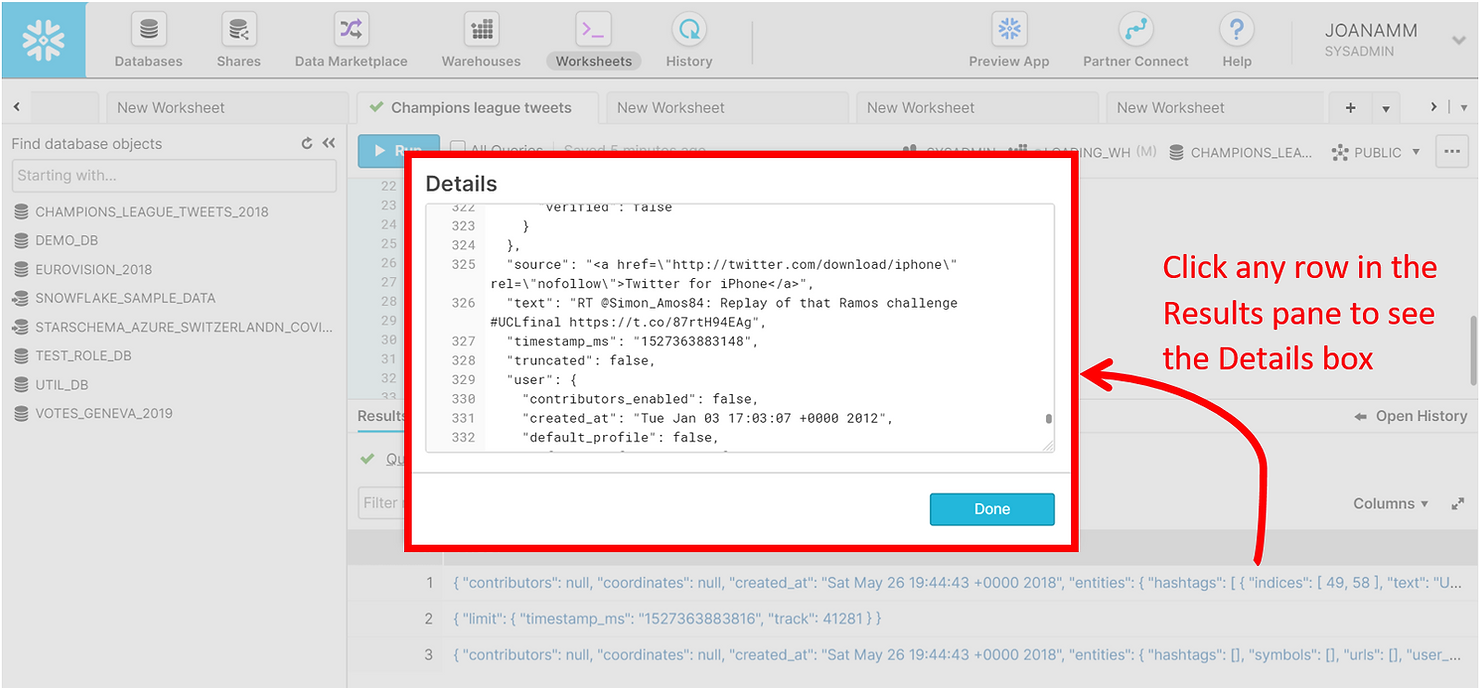
Le tweet JSON est composé de plusieurs entités imbriquées, chacune ayant des paires clé-valeur différentes. Les regarder dans la capture d'écran ci-dessus peut sembler intimidant, mais naviguer dans les données JSON dans Snowflake est en fait simple : il suffit de créer des chemins à l'aide de deux points. Dans l'exemple ci-dessous, nous récupérons l'identifiant utilisateur des 10 premiers tweets.
SELECT tweet:user:id AS user_id FROM raw_tweets
LIMIT 10;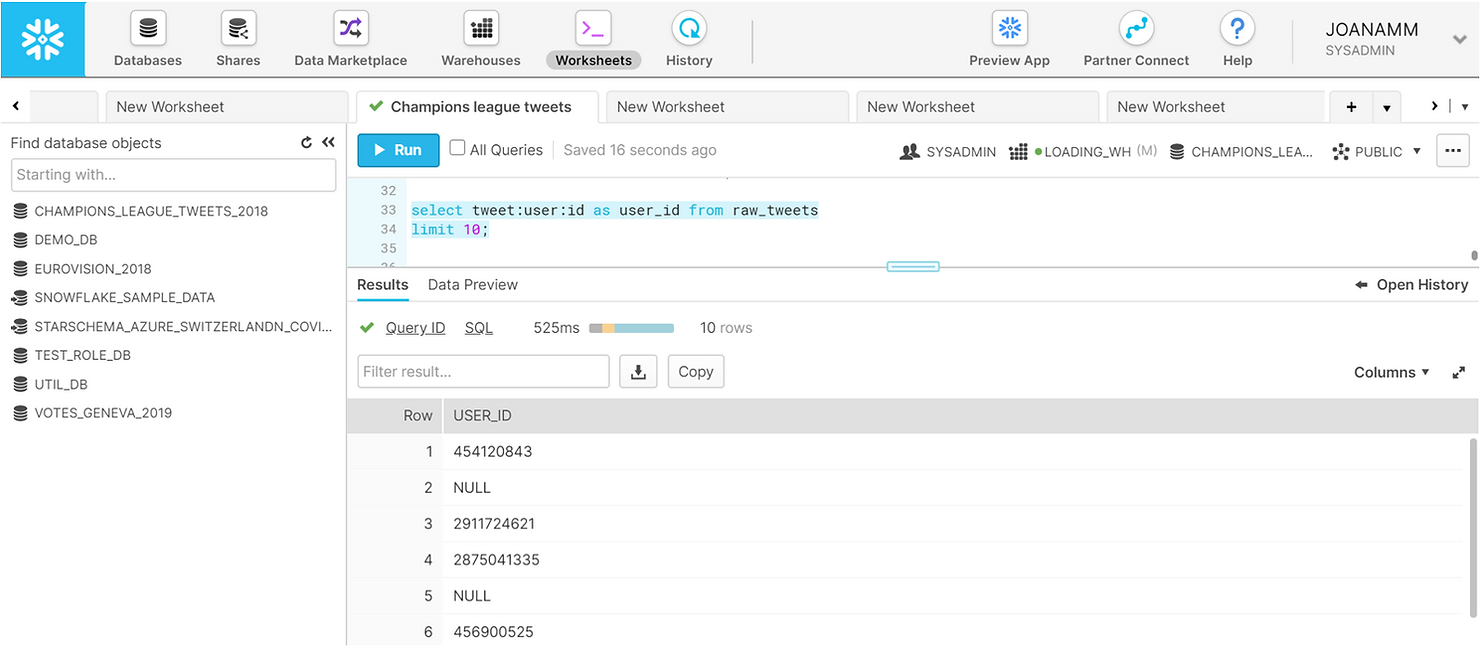
Nous pouvons facilement récupérer plus d'informations à partir des tweets et obtenir un aperçu structuré et tabulaire familier des données dans le volet des résultats.
SELECT tweet:user:id AS user_id,
tweet:user:followers_count AS user_followers_count,
tweet:id AS tweet_id,
tweet:created_at AS tweet_date,
tweet:lang AS tweet_language,
tweet:text AS tweet_text,
tweet:entities:hashtags AS tweet_hashtags
FROM raw_tweets
LIMIT 10;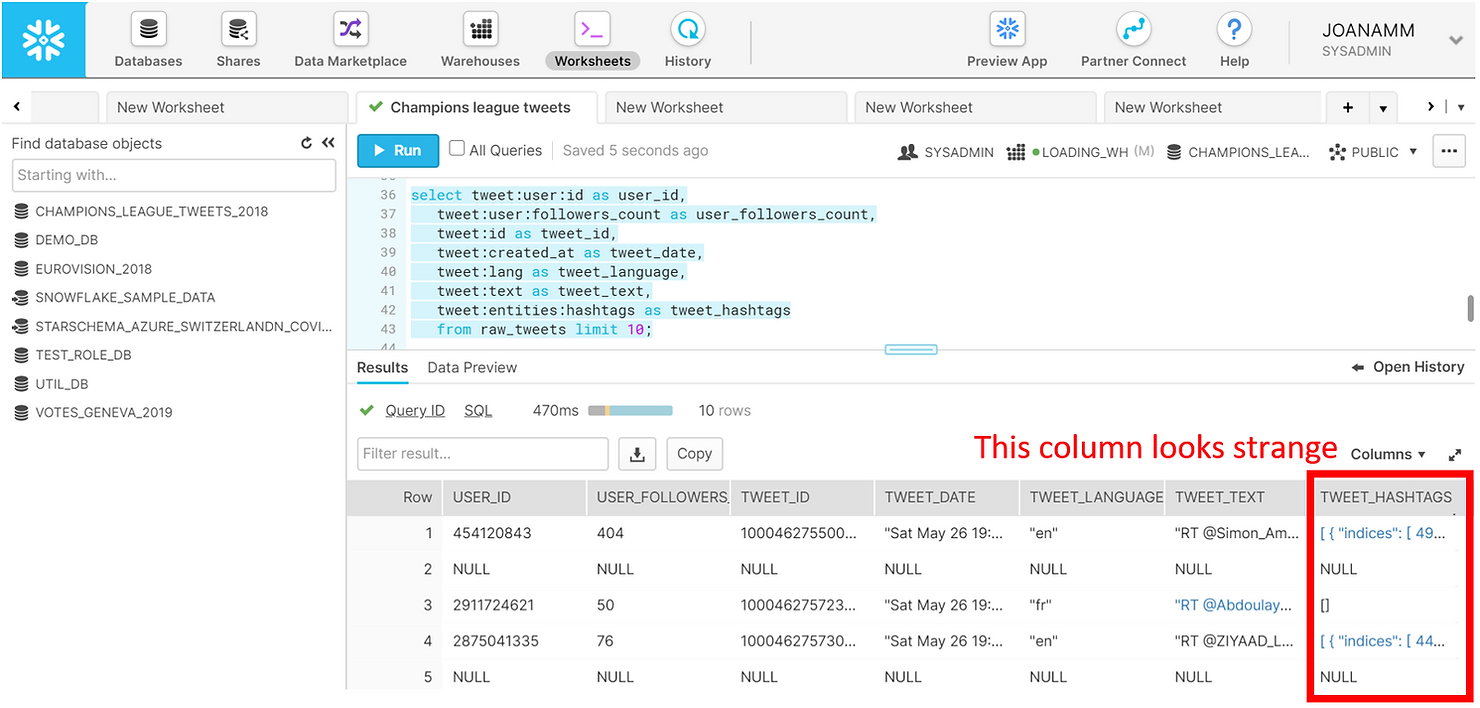
Notez cependant que la dernière colonne contient les hashtags. Nous pouvons cliquer dessus dans le volet des résultats pour en savoir plus.
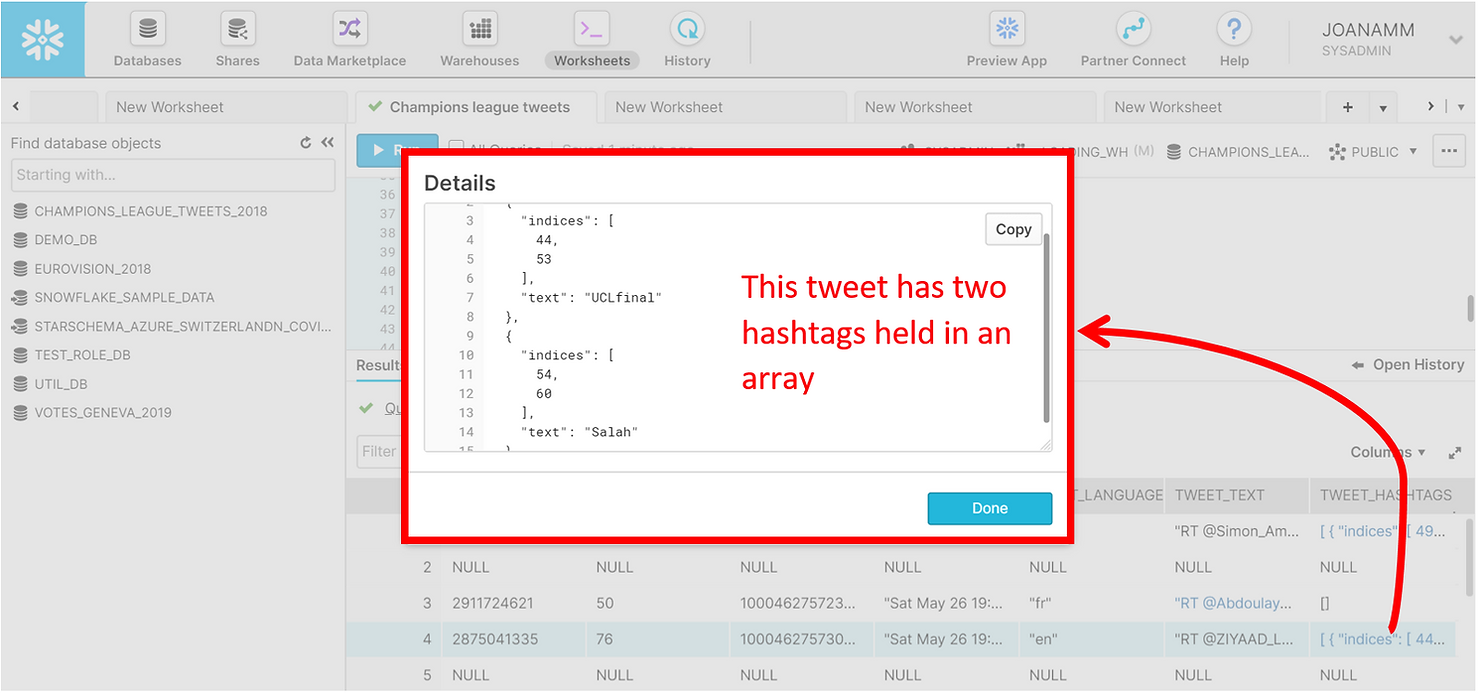
Un seul tweet peut contenir plusieurs hashtags, qui sont en fait regroupés dans des tableaux. Pour voir tous les hashtags d'un tweet sous forme de tableau, nous devons aplatir les données. Encore une fois, il s'agit d'une opération simple dans Snowflake. Vous pouvez voir ci-dessous un aperçu des 10 premiers hashtags de l'ensemble de données. Remarquez comment un même tweet peut avoir plusieurs hashtags. Désormais, chaque ligne du volet des résultats n'est plus un tweet, mais un hashtag.
SELECT tweet:id AS tweet_id,
value:text AS tweet_hashtag_text
FROM raw_tweets,
LATERAL FLATTEN(tweet:entities:hashtags)
LIMIT 10;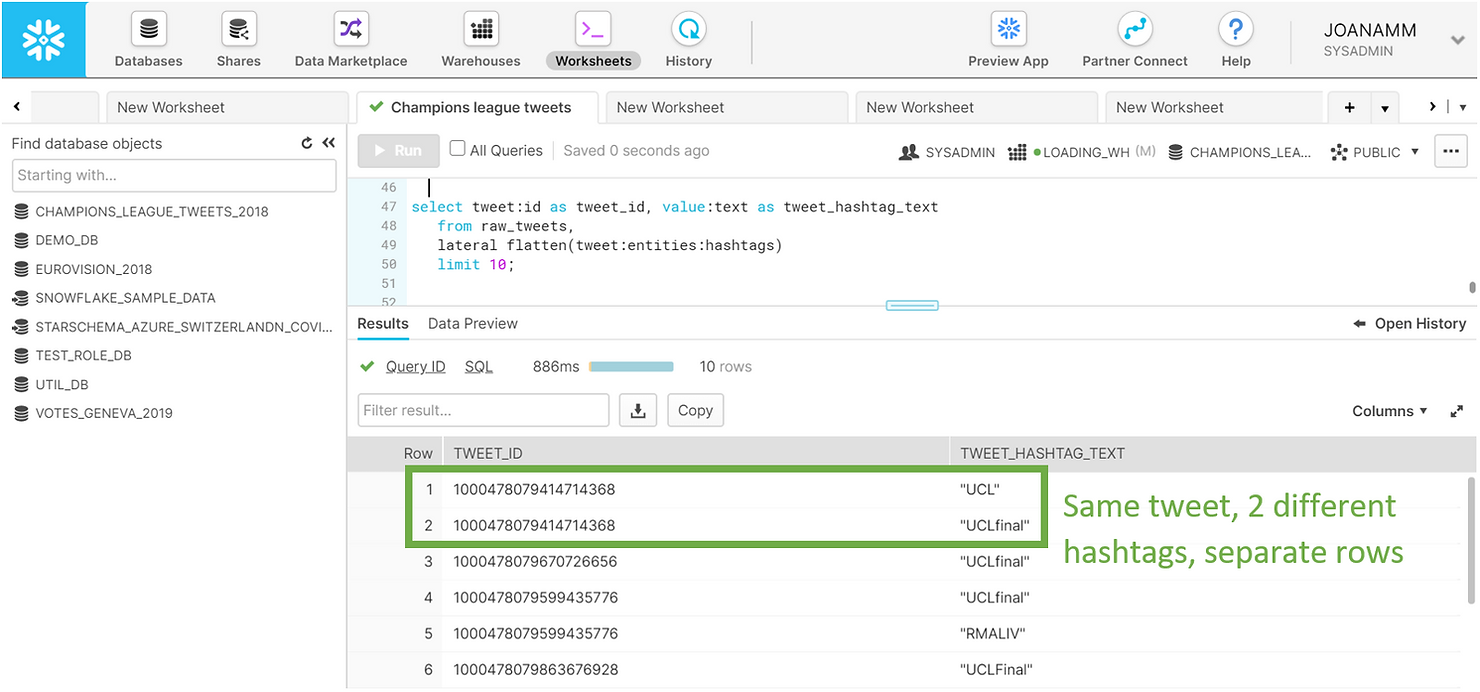
Comme nous l'avons montré, Snowflake vous permet d'utiliser de simples instructions SQL pour interroger un ensemble de données JSON complexe. Pour optimiser le processus d'analyse à venir, sauvegardons les résultats de ces requêtes dans une vue. Par rapport aux autres requêtes présentées ci-dessus, nous avons simplement converti les colonnes dans les types de données appropriés et filtré les données potentiellement sensibles.
CREATE OR REPLACE view summary_tweets AS
SELECT tweet:user:id::number AS user_id,
tweet:user:followers_count::integer AS user_followers_count,
tweet:id::number AS tweet_id,
tweet:created_at::timestamp AS tweet_date,
tweet:lang::string AS tweet_language,
tweet:text::string AS tweet_text,
value:text::string AS tweet_hashtag_text from raw_tweets,
LATERAL FLATTEN(tweet:entities:hashtags)
WHERE tweet_id IS NOT NULL AND tweet:possibly_sensitive=FALSE AND hour(tweet_date)>17;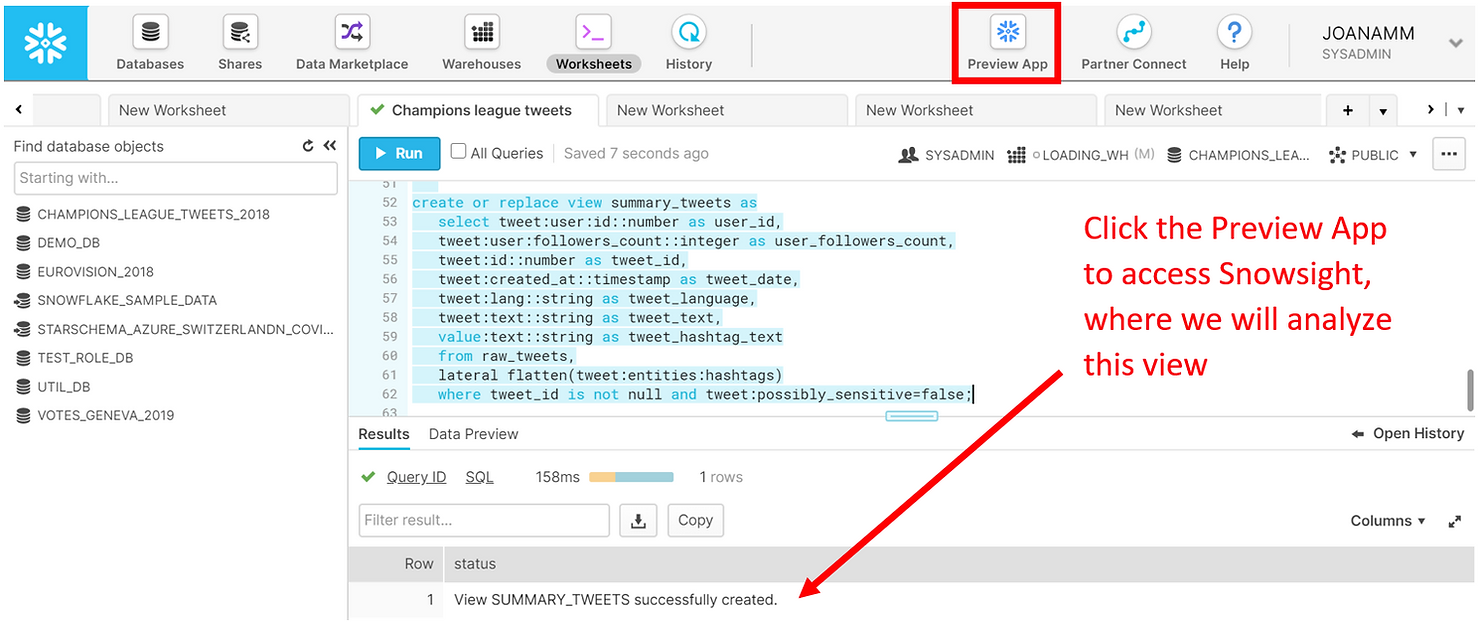
Analyser
Pour analyser nos tweets, nous utiliserons Viseur de neige, la nouvelle interface d'analyse de Snowflake. Snowsight est toujours en mode aperçu, mais il est actuellement accessible depuis l'application Preview en haut de l'interface utilisateur Web. Nous utiliserons les feuilles de travail, ainsi que la nouvelle fonctionnalité de tableaux de bord de Snowsight.
Si vous ouvrez une nouvelle feuille de travail dans Snowsight, vous constaterez peut-être qu'à l'exception d'une modification de conception, elle est très similaire aux feuilles de travail classiques utilisées ci-dessus. Par exemple, nous pouvons exécuter des instructions SQL comme auparavant, mais nous avons l'avantage supplémentaire de la saisie automatique. Ici, nous sélectionnons tous les hashtags de la vue SUMMARY_TWEETS que nous avons créée précédemment, et les résultats de notre requête apparaissent également dans le volet Résultats en bas.
SELECT UPPER(tweet_hashtag_text) FROM summary_tweets;

Cependant, une fonctionnalité puissante du tout nouveau Snowsight se débloque une fois que nous cliquons sur Chart.
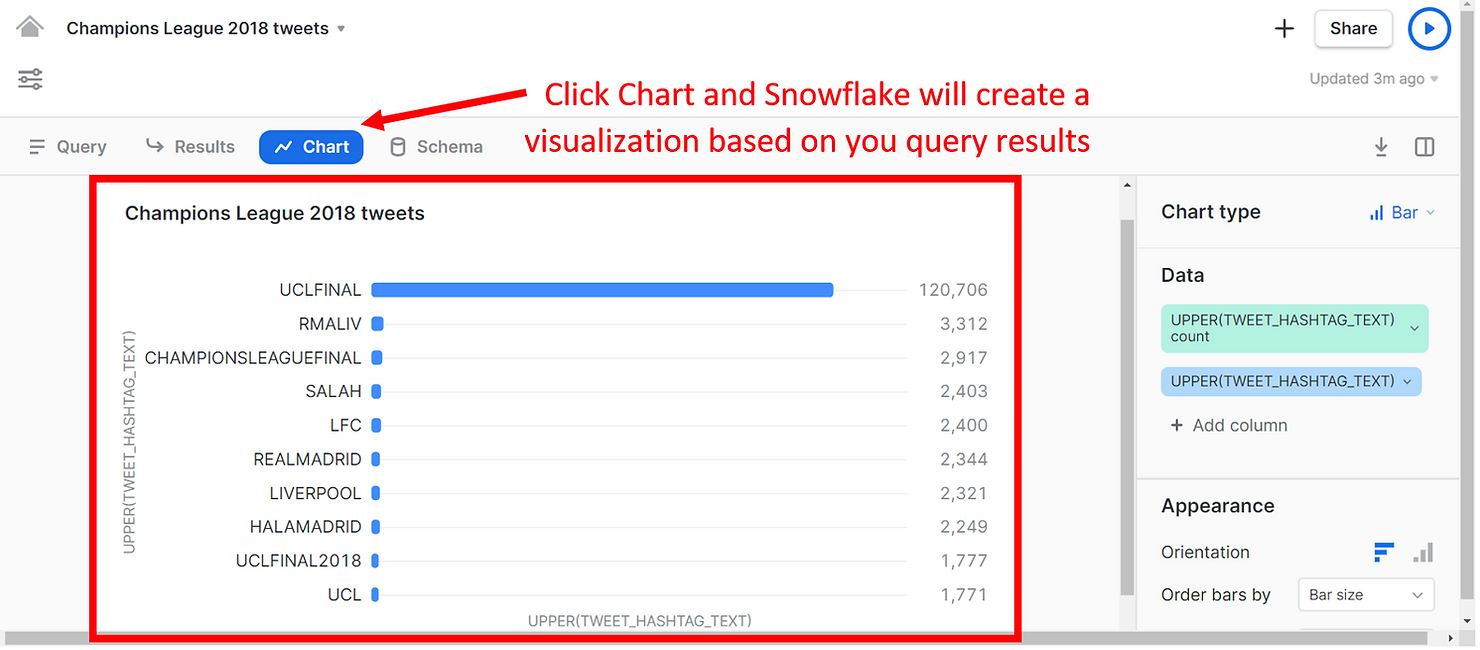
Comme vous pouvez le constater, Snowflake a automatiquement produit une visualisation indiquant la fréquence de chaque hashtag dans nos résultats, ce qui nous a permis de voir bien plus que ce que le volet Résultats avait à offrir. Le hashtag UCLFINAL a été utilisé le plus souvent - 120 000 fois. D'autres hashtags populaires font référence aux équipes qui ont joué en finale, à savoir le Real Madrid et Liverpool.
Voici un autre exemple simple, d'un graphique à barres du nombre de tweets par utilisateur. Vous pouvez utiliser le volet de droite pour modifier et mettre en forme les graphiques si vous le souhaitez.
SELECT user_id,
COUNT(distinct tweet_id) AS tweet_count
FROM summary_tweets
GROUP BY 1
ORDER BY tweet_count DESC
LIMIT 10;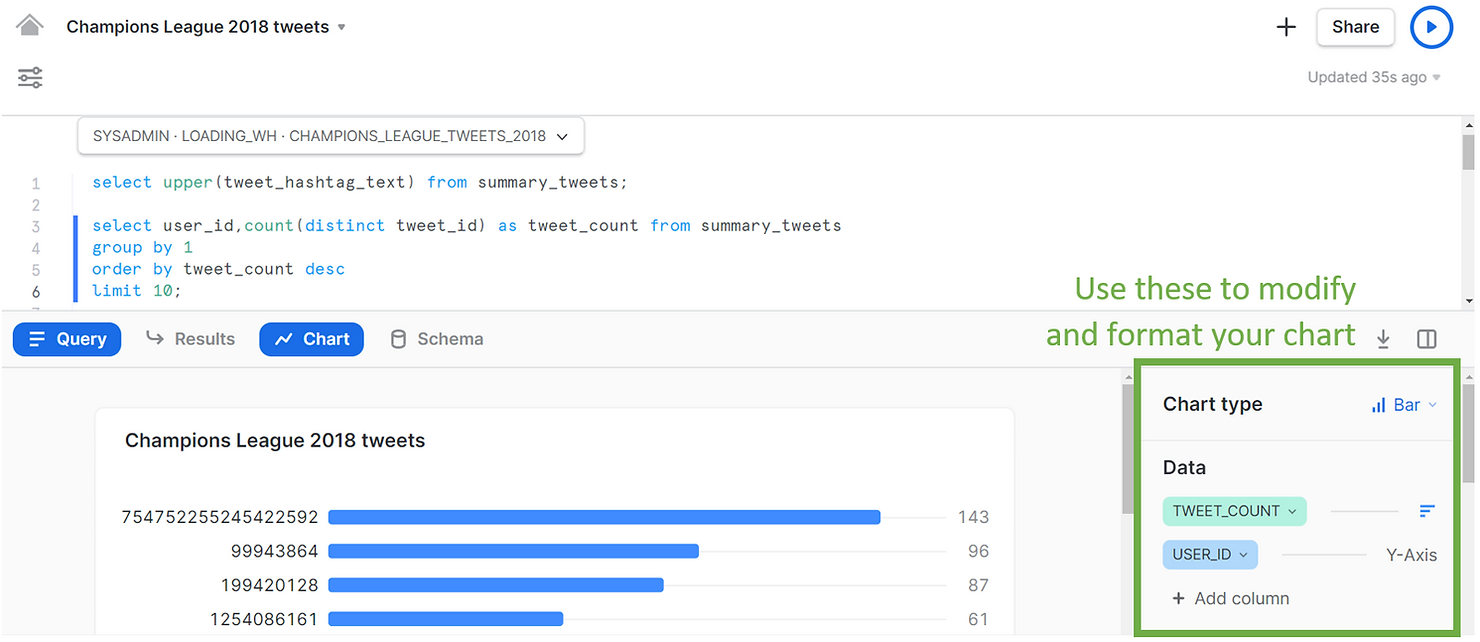
Ou encore un autre exemple, cette fois un graphique linéaire, montrant quand les différents tweets ont été créés.
SELECT tweet_date,
COUNT(DISTINCT tweet_id) AS tweet_count
FROM summary_tweets
GROUP BY tweet_date;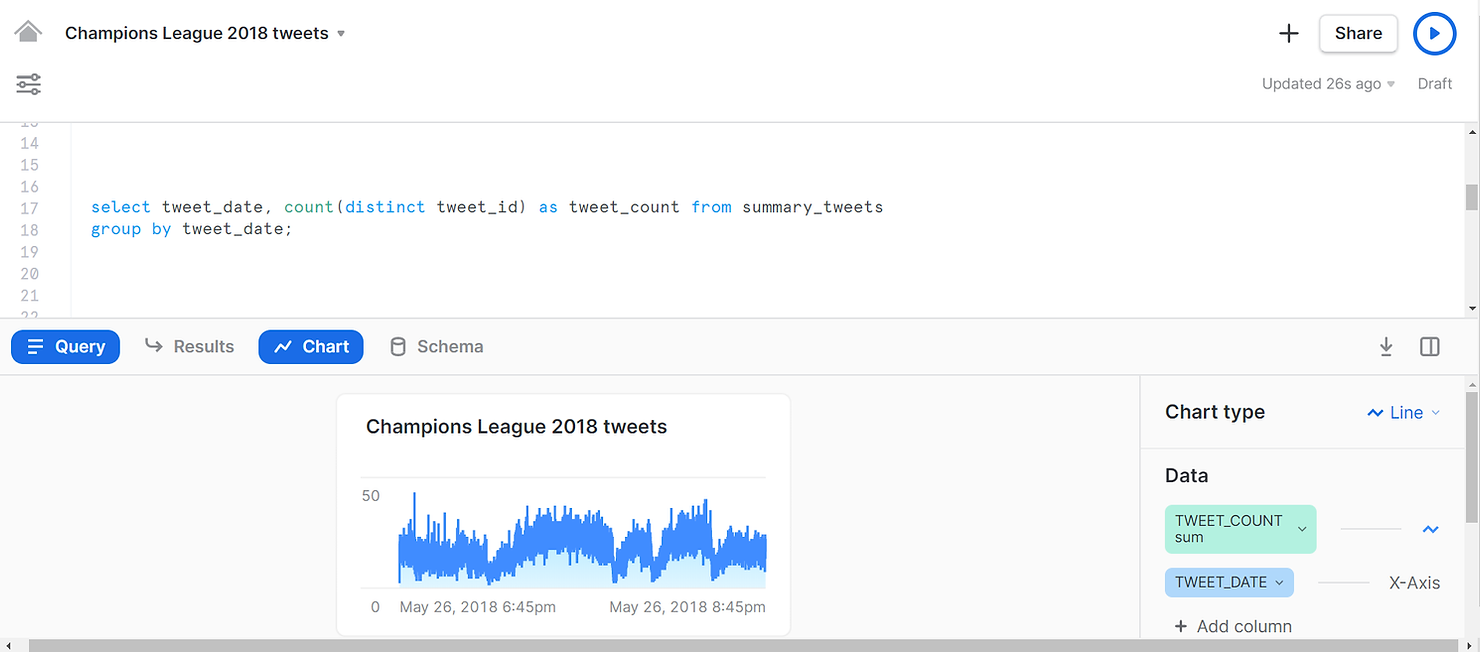
Et en quelques clics supplémentaires dans Snowsight, nous pouvons créer un tableau de bord pour résumer nos résultats, le tout dans Snowflake !
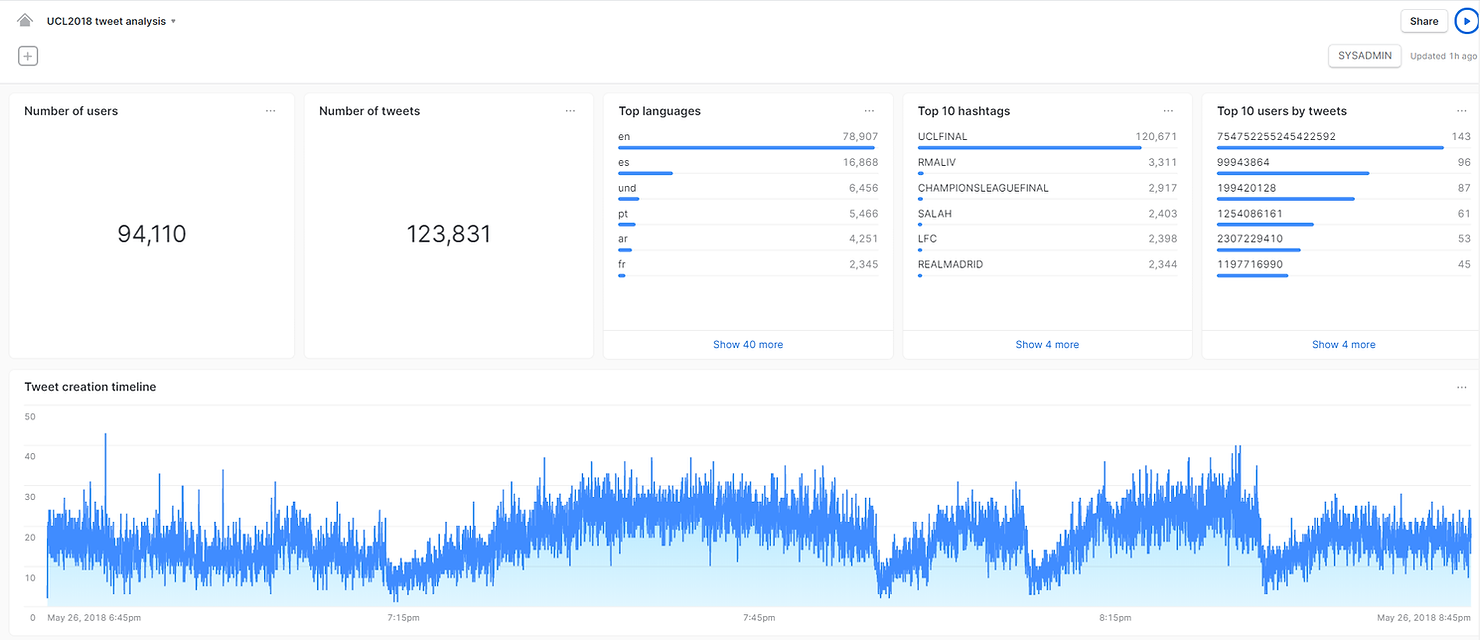
En résumé, Snowflake est une plateforme de données unique qui débloque les ressources illimitées du cloud et permet aux entreprises de devenir pilotées par les données dans un monde de données moderne. Nous espérons avoir pu vous montrer avec quelle rapidité et facilité vous pouvez passer d'un ensemble de données semi-structuré confus à un tableau de bord analytique, le tout dans Snowflake. Si vous êtes curieux de connaître Snowflake, contactez Team Argusa à l'adresse info@argusa.ch.
Flocon de neige est une plateforme de données intégrée unique, conçue de A à Z pour le cloud. Son architecture de données partagées multi-clusters brevetée comprend des couches de calcul, de stockage et de services cloud qui évoluent indépendamment, permettant à tout utilisateur de travailler avec n'importe quelle donnée, sans aucune limite d'échelle, de performance ou de flexibilité.
Snowflake prend en charge les entrepôts de données modernes, les lacs de données augmentés, la science des données avancée, le développement intensif d'applications, les échanges de données sécurisés et l'ingénierie des données intégrée, le tout en un seul endroit, permettant aux professionnels des données et de la BI de tirer le meilleur parti de leurs données. Plus important encore, Snowflake est sécurisé et régi par sa conception, et est fourni en tant que service ne nécessitant pratiquement aucune maintenance.
Le cloud de données Snowflake offre des fonctionnalités vraiment puissantes. Par exemple, sa gestion des métadonnées permet le clonage zéro copie et le voyage dans le temps. La couche de calcul peut être étendue et dédimensionnée à tout moment pour gérer des charges de travail complexes et simultanées, et vous ne payez que pour ce que vous utilisez. En outre, le stockage et le calcul sont séparés, ce qui garantit que tout le monde peut accéder aux données sans avoir à se heurter à des problèmes de contentieux.
L'une des fonctionnalités les plus intéressantes de Snowflake est sa prise en charge native des données semi-structurées. Avec Snowflake, il n'est pas nécessaire de mettre en œuvre des systèmes distincts pour traiter les données structurées et semi-structurées, ce qui est crucial à l'heure actuelle du Big Data et de l'IoT. Le processus de chargement d'un fichier CSV ou JSON est identique et fluide. De plus, Snowflake est une plate-forme SQL qui vous permet d'interroger des données structurées et semi-structurées à l'aide de SQL avec des performances similaires, sans avoir besoin d'acquérir de nouvelles compétences en programmation.
Nous allons montrer ici, à l'aide d'un exemple simple, à quel point il est facile de charger, d'interroger et d'analyser des données semi-structurées dans Snowflake. Nous examinerons spécifiquement les données de Twitter. Cela est particulièrement intéressant compte tenu du volume de données produit par Twitter et du fait que le modèle de données de Twitter repose sur des données semi-structurées, les tweets étant généralement codés en JSON.
Suivez-moi
Si vous souhaitez une expérience plus pratique, vous pouvez créer votre propre compte Snowflake et suivre notre exemple en copiant et collant le code. Veuillez visiter Snowflake ici pour vous inscrire à un essai gratuit. Snowflake étant fourni en tant que service, il vous suffit de choisir une édition de Snowflake (nous recommandons Entreprise) et une plateforme/région cloud — AWS, Azure ou GCP (Snowflake étant indépendant du cloud, votre expérience sera similaire quelle que soit la plateforme que vous choisissez).
Nous jouerons avec un jeu de données JSON contenant des tweets capturés lors de la finale de l'UEFA Champions League 2018. Vous pouvez télécharger le fichier JSON - TweetsChampions.json - directement sur votre ordinateur depuis kaggle. En raison des restrictions de taille de fichier, nous utiliserons Snow SQL, le client de ligne de commande de Snowflake, pour charger les données de notre ordinateur dans Snowflake. Pour installer SnowSQL, rendez-vous sur Référentiel de Snowflake.
Chargement
Commençons par mettre les choses en place. Ci-dessous, vous pouvez voir une capture d'écran de l'interface Web de Snowflake. Il s'agit d'un outil extrêmement puissant qui peut être utilisé pour effectuer presque toutes les tâches dans Snowflake. Ici, nous utiliserons spécifiquement les feuilles de travail pour créer et soumettre des requêtes et des opérations SQL. Remarquez comment les résultats SQL apparaissent en bas de la page. N'oubliez pas que la plupart de ces opérations peuvent être exécutées à l'aide d'autres fonctionnalités de l'interface Web qui ne nécessitent pas l'écriture de code SQL.
Nous avons commencé par créer un entrepôt de taille moyenne nommé « LOADING_WH ». Les entrepôts de Snowflake sont des unités informatiques virtuelles qui fournissent la puissance de calcul nécessaire à l'exécution des requêtes. Cet entrepôt est constitué d'un cluster de 4 serveurs. Nous avons défini max_cluster_count = 2, ce qui signifie que nous autorisons Snowflake à ajouter automatiquement un autre cluster à l'entrepôt virtuel, afin d'améliorer les performances au cas où plusieurs requêtes seraient soumises simultanément. N'oubliez pas qu'avec Snowflake, vous ne payez pour le calcul que lorsque les entrepôts fonctionnent. Nous avons donc configuré notre LOADING_WH pour qu'il se suspende automatiquement dans les 60 secondes suivant l'inactivité. Pour simplifier notre charge de travail, nous avons également utilisé l'option auto_resume = true, qui lance automatiquement l'entrepôt une fois qu'une requête est soumise. L'opération use warehouse Loading_WH indique que les requêtes soumises dans la feuille de travail utiliseront cet entrepôt pour la puissance de calcul.
CREATE OR REPLACE WAREHOUSE loading_WH
WAREHOUSE_SIZE = 'medium'
AUTO_SUSPEND = 60
AUTO_RESUME = true
MIN_CLUSTER_COUNT = 1
MAX_CLUSTER_COUNT = 2;
USE WAREHOUSE loading_WH;Nous avons également créé une base de données CHAMPIONS_LEAGUE_TWEETS_2018 pour stocker nos données, et nous avons choisi d'utiliser le schéma PUBLIC créé automatiquement dans cette base de données pour plus de simplicité. Nous avons également indiqué que nous utiliserons cette base de données et ces schémas dans le contexte de la feuille de travail.
CREATE OR REPLACE DATABASE champions_league_tweets_2018
COMMENT = 'https://www.kaggle.com/xvivancos/tweets-during-r-madrid-vs-liverpool-ucl-2018';
USE DATABASE champions_league_tweets_2018;
USE SCHEMA public;Pour charger des données dans Snowflake, vous devez généralement suivre les étapes suivantes :
- Créez un format de fichier pour informer Snowflake du type de données que vous allez charger. Snowflake prend en charge le chargement de données structurées (CSV, TSV,...) et semi-structurées (JSON, Avro, ORC, Parquet et XML). Ici, nous avons simplement créé un objet de format de fichier pour les fichiers JSON nommé TWEETS_FILE_FORMAT.
CREATE OR REPLACE FILE_FORMAT tweets_file_format
TYPE = json;- Créez ce que l'on appelle une scène. Une étape est une zone intermédiaire dans laquelle vous allez placer vos fichiers de données avant de les charger dans des tableaux. Les étapes de Snowflake peuvent être internes (elles existent dans Snowflake) ou externes (par exemple, un compartiment AWS S3). Pour cet exemple, nous avons créé un stage interne appelé TWEETS_STAGE. Nous avons également fait référence au format de fichier créé précédemment dans la définition de la scène, car celle-ci contiendra des fichiers JSON. Nous avons ensuite utilisé Snow SQL pour placer notre fichier de données JSON dans cette étape interne. Une fois les données placées dans la scène, vous pouvez répertorier leur contenu. Dans la capture d'écran ci-dessous, vous trouverez le résultat de la commande list. Remarquez comment le fichier JSON est compressé. C'est standard dans Snowflake et cela se fait automatiquement.
CREATE OR REPLACE STAGE tweets_stage
FILE_FORMAT = tweets_file_format;
//use SnowSQL to run the put command and stage local json file
//put file://C:\temp\TweetsChampions.json @tweets_stage;
LIST @tweets_stage;- Créez un tableau contenant vos données. Les données semi-structurées sont notamment chargées dans des tables comportant une seule colonne de type VARIANT. Il s'agit d'un type de données innovant et flexible développé par Snowflake, spécifiquement pour contenir une variété de données semi-structurées.
CREATE OR REPLACE TABLE raw_tweets (tweet variant);Tout est maintenant en place pour charger les données, et il ne nous reste plus qu'à les copier de la scène dans le tableau. Snowflake sait comment analyser et identifier la structure du fichier JSON. En un peu plus d'une minute, nous avons pu remplir notre tableau RAW_TWEETS d'environ 350 000 lignes, soit 1 ligne par tweet.
COPY INTO raw_tweets FROM @tweets_stage;
Interrogation
Maintenant que les données ont été chargées, nous pouvons exécuter une simple instruction SELECT sur la table RAW_TWEETS et explorer à quoi ressemble chacune des lignes en cliquant dessus dans le panneau des résultats de l'interface utilisateur Web.
SELECT tweet FROM raw_tweets LIMIT 3;
Le tweet JSON est composé de plusieurs entités imbriquées, chacune ayant des paires clé-valeur différentes. Les regarder dans la capture d'écran ci-dessus peut sembler intimidant, mais naviguer dans les données JSON dans Snowflake est en fait simple : il suffit de créer des chemins à l'aide de deux points. Dans l'exemple ci-dessous, nous récupérons l'identifiant utilisateur des 10 premiers tweets.
SELECT tweet:user:id AS user_id FROM raw_tweets
LIMIT 10;Nous pouvons facilement récupérer plus d'informations à partir des tweets et obtenir un aperçu structuré et tabulaire familier des données dans le volet des résultats.
SELECT tweet:user:id AS user_id,
tweet:user:followers_count AS user_followers_count,
tweet:id AS tweet_id,
tweet:created_at AS tweet_date,
tweet:lang AS tweet_language,
tweet:text AS tweet_text,
tweet:entities:hashtags AS tweet_hashtags
FROM raw_tweets
LIMIT 10;Notez cependant que la dernière colonne contient les hashtags. Nous pouvons cliquer dessus dans le volet des résultats pour en savoir plus.
Un seul tweet peut contenir plusieurs hashtags, qui sont en fait regroupés dans des tableaux. Pour voir tous les hashtags d'un tweet sous forme de tableau, nous devons aplatir les données. Encore une fois, il s'agit d'une opération simple dans Snowflake. Vous pouvez voir ci-dessous un aperçu des 10 premiers hashtags de l'ensemble de données. Remarquez comment un même tweet peut avoir plusieurs hashtags. Désormais, chaque ligne du volet des résultats n'est plus un tweet, mais un hashtag.
SELECT tweet:id AS tweet_id,
value:text AS tweet_hashtag_text
FROM raw_tweets,
LATERAL FLATTEN(tweet:entities:hashtags)
LIMIT 10;Comme nous l'avons montré, Snowflake vous permet d'utiliser de simples instructions SQL pour interroger un ensemble de données JSON complexe. Pour optimiser le processus d'analyse à venir, sauvegardons les résultats de ces requêtes dans une vue. Par rapport aux autres requêtes présentées ci-dessus, nous avons simplement converti les colonnes dans les types de données appropriés et filtré les données potentiellement sensibles.
CREATE OR REPLACE view summary_tweets AS
SELECT tweet:user:id::number AS user_id,
tweet:user:followers_count::integer AS user_followers_count,
tweet:id::number AS tweet_id,
tweet:created_at::timestamp AS tweet_date,
tweet:lang::string AS tweet_language,
tweet:text::string AS tweet_text,
value:text::string AS tweet_hashtag_text from raw_tweets,
LATERAL FLATTEN(tweet:entities:hashtags)
WHERE tweet_id IS NOT NULL AND tweet:possibly_sensitive=FALSE AND hour(tweet_date)>17;Analyser
Pour analyser nos tweets, nous utiliserons Viseur de neige, la nouvelle interface d'analyse de Snowflake. Snowsight est toujours en mode aperçu, mais il est actuellement accessible depuis l'application Preview en haut de l'interface utilisateur Web. Nous utiliserons les feuilles de travail, ainsi que la nouvelle fonctionnalité de tableaux de bord de Snowsight.
Si vous ouvrez une nouvelle feuille de travail dans Snowsight, vous constaterez peut-être qu'à l'exception d'une modification de conception, elle est très similaire aux feuilles de travail classiques utilisées ci-dessus. Par exemple, nous pouvons exécuter des instructions SQL comme auparavant, mais nous avons l'avantage supplémentaire de la saisie automatique. Ici, nous sélectionnons tous les hashtags de la vue SUMMARY_TWEETS que nous avons créée précédemment, et les résultats de notre requête apparaissent également dans le volet Résultats en bas.
SELECT UPPER(tweet_hashtag_text) FROM summary_tweets;
Cependant, une fonctionnalité puissante du tout nouveau Snowsight se débloque une fois que nous cliquons sur Chart.
Comme vous pouvez le constater, Snowflake a automatiquement produit une visualisation indiquant la fréquence de chaque hashtag dans nos résultats, ce qui nous a permis de voir bien plus que ce que le volet Résultats avait à offrir. Le hashtag UCLFINAL a été utilisé le plus souvent - 120 000 fois. D'autres hashtags populaires font référence aux équipes qui ont joué en finale, à savoir le Real Madrid et Liverpool.
Voici un autre exemple simple, d'un graphique à barres du nombre de tweets par utilisateur. Vous pouvez utiliser le volet de droite pour modifier et mettre en forme les graphiques si vous le souhaitez.
SELECT user_id,
COUNT(distinct tweet_id) AS tweet_count
FROM summary_tweets
GROUP BY 1
ORDER BY tweet_count DESC
LIMIT 10;Ou encore un autre exemple, cette fois un graphique linéaire, montrant quand les différents tweets ont été créés.
SELECT tweet_date,
COUNT(DISTINCT tweet_id) AS tweet_count
FROM summary_tweets
GROUP BY tweet_date;Et en quelques clics supplémentaires dans Snowsight, nous pouvons créer un tableau de bord pour résumer nos résultats, le tout dans Snowflake !
En résumé, Snowflake est une plateforme de données unique qui débloque les ressources illimitées du cloud et permet aux entreprises de devenir pilotées par les données dans un monde de données moderne. Nous espérons avoir pu vous montrer avec quelle rapidité et facilité vous pouvez passer d'un ensemble de données semi-structuré confus à un tableau de bord analytique, le tout dans Snowflake. Si vous êtes curieux de connaître Snowflake, contactez Team Argusa à l'adresse info@argusa.ch.